简介
Sequicity: Simplifying Task-oriented Dialogue Systems with Single Sequence-to-Sequence Architectures, acl2018, pdf, pytorch code
本文是针对任务型对话提出的一种end2end的模型,名为Sequicity。该模型是一种seq2seq+Two Stage CopyNet的结构。
优点:
- 1.相对于pipeline的结构,复杂度低,参数少,训练时间短。
- 2.针对oov的数据,还能保持不错的实体匹配率。
- 3.可以同时完成task completion和response generation。
结构细节
Belief Span (bspan)
在Belief Span的术语中:一个slot可以是informable 或者requestable。所谓informable是指这个slot是作为知识库搜索时的限制条件,比如食物类型food_type,如果设定成chinese food,则搜索时返回的餐馆必须是中餐馆;所谓requestable是指这个slot可以被用户指定返回,比如用户需要知道餐馆的类型,slotaddress就会被置为true,后面的回答就必须包含餐馆的地址。
Sequicity
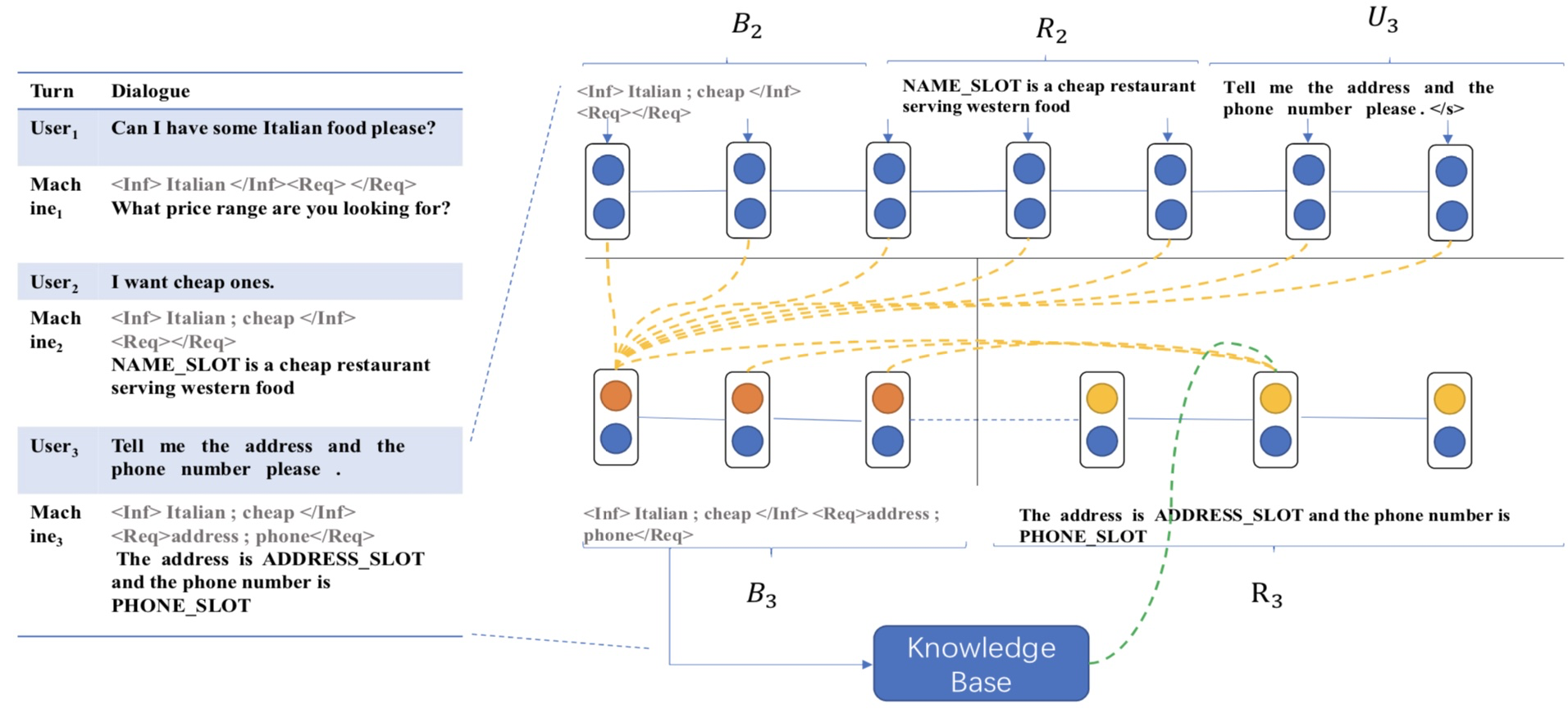
模型的输入(图中上层)是上一轮的bspan,上一轮的系统回答,本轮的用户输入;输出(图中下层)是更新的bspan和本轮系统回答。
输入先是过了一个统一的encoder,然后再分别过一个bspan的decoder,再拿这个decoder的结果再过response的decoder,生成最终的response。
上面的两步也正对应着两步的copy net:1.计算生成的词分布和输入的词分布,将二者叠加获得新的词分布,生成bspan decoder的输出;2.将生成的次分布和bsapn decoder的词分布叠加,生成response decoder的词分布。
实验
数据集: CamRest676 (Wen et al., 2017a) and KVRET (Eric and Manning, 2017b)
样例:
1 | { |
指标:
- BLEU
- Entity match rate evaluates task completion.
- Success F1
结果:
指标超过各个baseline模型。