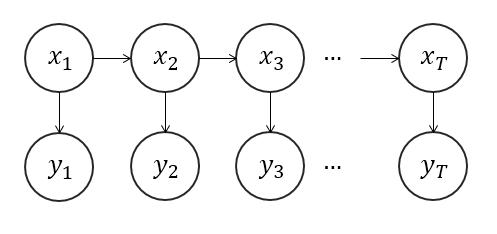
defdraw_from(probs): """ 1.np.random.multinomial: 按照多项式分布,生成数据 >>> np.random.multinomial(20, [1/6.]*6, size=2) array([[3, 4, 3, 3, 4, 3], [2, 4, 3, 4, 0, 7]]) For the first run, we threw 3 times 1, 4 times 2, etc. For the second, we threw 2 times 1, 4 times 2, etc. 2.np.where: >>> x = np.arange(9.).reshape(3, 3) >>> np.where( x > 5 ) (array([2, 2, 2]), array([0, 1, 2])) """ return np.where(np.random.multinomial(1,probs) == 1)[0][0]
observations = np.zeros(T, dtype=int) states = np.zeros(T, dtype=int) states[0] = draw_from(pi) observations[0] = draw_from(B[states[0],:]) for t inrange(1, T): states[t] = draw_from(A[states[t-1],:]) observations[t] = draw_from(B[states[t],:]) return observations, states
defgenerate_index_map(lables): id2label = {} label2id = {} i = 0 for l in lables: id2label[i] = l label2id[l] = i i += 1 return id2label, label2id states_id2label, states_label2id = generate_index_map(states) observations_id2label, observations_label2id = generate_index_map(observations) print(states_id2label, states_label2id) print(observations_id2label, observations_label2id)
defconvert_map_to_vector(map_, label2id): """将概率向量从dict转换成一维array""" v = np.zeros(len(map_), dtype=float) for e in map_: v[label2id[e]] = map_[e] return v
defconvert_map_to_matrix(map_, label2id1, label2id2): """将概率转移矩阵从dict转换成矩阵""" m = np.zeros((len(label2id1), len(label2id2)), dtype=float) for line in map_: for col in map_[line]: m[label2id1[line]][label2id2[col]] = map_[line][col] return m
1 2 3 4 5 6 7
A = convert_map_to_matrix(transition_probability, states_label2id, states_label2id) print(A) B = convert_map_to_matrix(emission_probability, states_label2id, observations_label2id) print(B) observations_index = [observations_label2id[o] for o in observations] pi = convert_map_to_vector(start_probability, states_label2id) print(pi)
# 生成模拟数据 observations_data, states_data = simulate(10) print(observations_data) print(states_data) # 相应的label print("病人的状态: ", [states_id2label[index] for index in states_data]) print("病人的观测: ", [observations_id2label[index] for index in observations_data])
defviterbi(obs_seq, A, B, pi): """ Returns ------- V : numpy.ndarray V [s][t] = Maximum probability of an observation sequence ending at time 't' with final state 's' prev : numpy.ndarray Contains a pointer to the previous state at t-1 that maximizes V[state][t] V对应δ,prev对应ψ """ N = A.shape[0] T = len(obs_seq) prev = np.zeros((T - 1, N), dtype=int)
# DP matrix containing max likelihood of state at a given time V = np.zeros((N, T)) V[:,0] = pi * B[:,obs_seq[0]]
for t inrange(1, T): for n inrange(N): seq_probs = V[:,t-1] * A[:,n] * B[n, obs_seq[t]] prev[t-1,n] = np.argmax(seq_probs) V[n,t] = np.max(seq_probs)
return V, prev
defbuild_viterbi_path(prev, last_state): """Returns a state path ending in last_state in reverse order. 最优路径回溯 """ T = len(prev) yield(last_state) for i inrange(T-1, -1, -1): yield(prev[i, last_state]) last_state = prev[i, last_state] defobservation_prob(obs_seq): """ P( entire observation sequence | A, B, pi ) """ return np.sum(forward(obs_seq)[:,-1])
defstate_path(obs_seq, A, B, pi): """ Returns ------- V[last_state, -1] : float Probability of the optimal state path path : list(int) Optimal state path for the observation sequence """ V, prev = viterbi(obs_seq, A, B, pi) # Build state path with greatest probability last_state = np.argmax(V[:,-1]) path = list(build_viterbi_path(prev, last_state))
return V[last_state,-1], reversed(path)
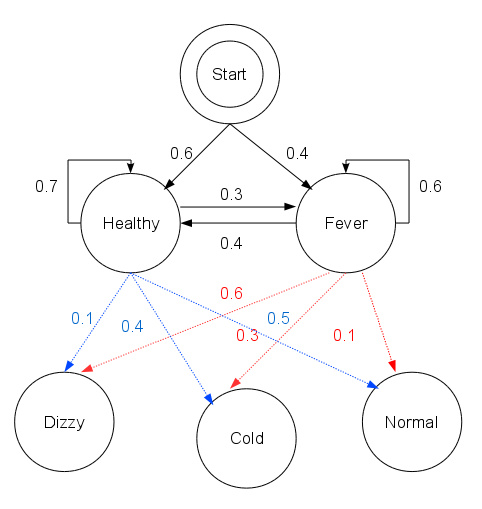
继续感冒预测的例子,根据刚才学得的模型参数,再去预测状态序列,观测准确率。
1 2 3 4 5 6 7
states_out = state_path(observations_data, newA, newB, newpi)[1] p = 0.0 for s in states_data: ifnext(states_out) == s: p += 1
print(p / len(states_data))
1
0.54
因为是随机生成的样本,因此准确率较低也可以理解。
使用Viterbi算法计算病人的病情以及相应的概率:
1 2 3 4 5 6 7 8 9 10 11 12 13
A = convert_map_to_matrix(transition_probability, states_label2id, states_label2id) B = convert_map_to_matrix(emission_probability, states_label2id, observations_label2id) observations_index = [observations_label2id[o] for o in observations] pi = convert_map_to_vector(start_probability, states_label2id) V, p = viterbi(observations_index, newA, newB, newpi) print(" " * 7, " ".join(("%10s" % observations_id2label[i]) for i in observations_index)) for s inrange(0, 2): print("%7s: " % states_id2label[s] + " ".join("%10s" % ("%f" % v) for v in V[s])) print('\nThe most possible states and probability are:') p, ss = state_path(observations_index, newA, newB, newpi) for s in ss: print(states_id2label[s]) print(p)
classHMM: """ Order 1 Hidden Markov Model Attributes ---------- A : numpy.ndarray State transition probability matrix B: numpy.ndarray Output emission probability matrix with shape(N, number of output types) pi: numpy.ndarray Initial state probablity vector """ def__init__(self, A, B, pi): self.A = A self.B = B self.pi = pi defsimulate(self, T): defdraw_from(probs): """ 1.np.random.multinomial: 按照多项式分布,生成数据 >>> np.random.multinomial(20, [1/6.]*6, size=2) array([[3, 4, 3, 3, 4, 3], [2, 4, 3, 4, 0, 7]]) For the first run, we threw 3 times 1, 4 times 2, etc. For the second, we threw 2 times 1, 4 times 2, etc. 2.np.where: >>> x = np.arange(9.).reshape(3, 3) >>> np.where( x > 5 ) (array([2, 2, 2]), array([0, 1, 2])) """ return np.where(np.random.multinomial(1,probs) == 1)[0][0]
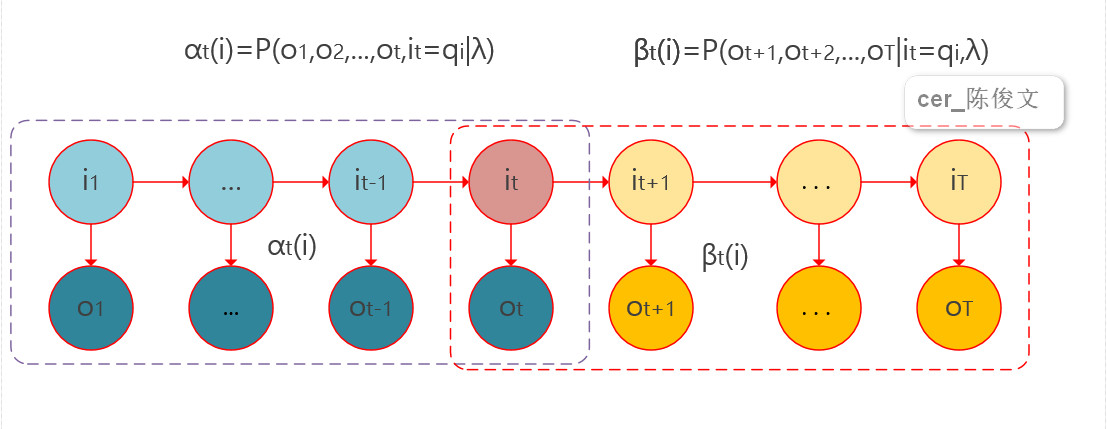
observations = np.zeros(T, dtype=int) states = np.zeros(T, dtype=int) states[0] = draw_from(self.pi) observations[0] = draw_from(self.B[states[0],:]) for t inrange(1, T): states[t] = draw_from(self.A[states[t-1],:]) observations[t] = draw_from(self.B[states[t],:]) return observations,states def_forward(self, obs_seq): """前向算法""" N = self.A.shape[0] T = len(obs_seq)
F = np.zeros((N,T)) F[:,0] = self.pi * self.B[:, obs_seq[0]]
for t inrange(1, T): for n inrange(N): F[n,t] = np.dot(F[:,t-1], (self.A[:,n])) * self.B[n, obs_seq[t]]
return F def_backward(self, obs_seq): """后向算法""" N = self.A.shape[0] T = len(obs_seq)
X = np.zeros((N,T)) X[:,-1:] = 1
for t inreversed(range(T-1)): for n inrange(N): X[n,t] = np.sum(X[:,t+1] * self.A[n,:] * self.B[:, obs_seq[t+1]])
xi = np.zeros((n_states,n_states,n_samples-1)) for t inrange(n_samples-1): denom = np.dot(np.dot(alpha[:,t].T, self.A) * self.B[:,observations[t+1]].T, beta[:,t+1]) for i inrange(n_states): numer = alpha[i,t] * self.A[i,:] * self.B[:,observations[t+1]].T * beta[:,t+1].T xi[i,:,t] = numer / denom
# gamma_t(i) = P(q_t = S_i | O, hmm) gamma = np.sum(xi,axis=1) # Need final gamma element for new B prod = (alpha[:,n_samples-1] * beta[:,n_samples-1]).reshape((-1,1)) gamma = np.hstack((gamma, prod / np.sum(prod))) #append one more to gamma!!!
num_levels = self.B.shape[1] sumgamma = np.sum(gamma,axis=1) for lev inrange(num_levels): mask = observations == lev newB[:,lev] = np.sum(gamma[:,mask],axis=1) / sumgamma
if np.max(abs(self.pi - newpi)) < criterion and \ np.max(abs(self.A - newA)) < criterion and \ np.max(abs(self.B - newB)) < criterion: done = 1
self.A[:],self.B[:],self.pi[:] = newA,newB,newpi defobservation_prob(self, obs_seq): """ P( entire observation sequence | A, B, pi ) """ return np.sum(self._forward(obs_seq)[:,-1])
defstate_path(self, obs_seq): """ Returns ------- V[last_state, -1] : float Probability of the optimal state path path : list(int) Optimal state path for the observation sequence """ V, prev = self.viterbi(obs_seq)
# Build state path with greatest probability last_state = np.argmax(V[:,-1]) path = list(self.build_viterbi_path(prev, last_state))
return V[last_state,-1], reversed(path)
defviterbi(self, obs_seq): """ Returns ------- V : numpy.ndarray V [s][t] = Maximum probability of an observation sequence ending at time 't' with final state 's' prev : numpy.ndarray Contains a pointer to the previous state at t-1 that maximizes V[state][t] """ N = self.A.shape[0] T = len(obs_seq) prev = np.zeros((T - 1, N), dtype=int)
# DP matrix containing max likelihood of state at a given time V = np.zeros((N, T)) V[:,0] = self.pi * self.B[:,obs_seq[0]]
for t inrange(1, T): for n inrange(N): seq_probs = V[:,t-1] * self.A[:,n] * self.B[n, obs_seq[t]] prev[t-1,n] = np.argmax(seq_probs) V[n,t] = np.max(seq_probs)
return V, prev
defbuild_viterbi_path(self, prev, last_state): """Returns a state path ending in last_state in reverse order.""" T = len(prev) yield(last_state) for i inrange(T-1, -1, -1): yield(prev[i, last_state]) last_state = prev[i, last_state]