五. Sorting and Searching
1 | 对应本书第五章。 |
笔记
这章开始进入算法部分,讲解排序和查找。
二分查找
1 | from __future__ import print_function |
1 | False |
用Hash实现一个Map抽象数据类型
Hash碰到collision的时候一般有两种解决方法:
- 开放寻址(open addressing):寻找下一个空的slot;
- 链接法(Chaining):允许一个hash值对应的slot中可以存放多个元素。

使用Hash的Map,查找的理想的时间复杂度是$O(1)$。
实际上,对于占用度是$λ$的HashTable,开放寻址的线性探测的比较次数是:$\frac{1}{2}(1+\frac{1}{1−λ})$;链接法的比较次数是:$\frac{1}{2}(1+(\frac{1}{1−λ})^2)$。
1 | class HashTable: |
1 | H=HashTable() |
1 | [77, 44, 55, 20, 26, 93, 17, None, None, 31, 54] |
1 | H.data |
1 | ['bird', |
冒泡排序
默认从小到大排序。 两两比较,逆序则两两互换。
时间复杂度:$O(n^2)$
1 | def bubbleSort(alist): |
1 | [17, 20, 26, 31, 44, 54, 55, 77, 93] |
选择排序
每次找到第k大的数,移动到倒数第k位。
时间复杂度:$O(n^2)$
1 | def selectionSort(alist): |
1 | [17, 20, 26, 31, 44, 54, 55, 77, 93] |
插入排序
递归思想,前面的子序列先排完序,再插入下一个元素排序。
时间复杂度:$O(n^2)$
1 | def insertionSort(alist): |
1 | [17, 20, 26, 31, 44, 54, 55, 77, 93] |
希尔排序
使用由大到小的gap,将将list分割成几个sublist,对每个sublist做插入排序。
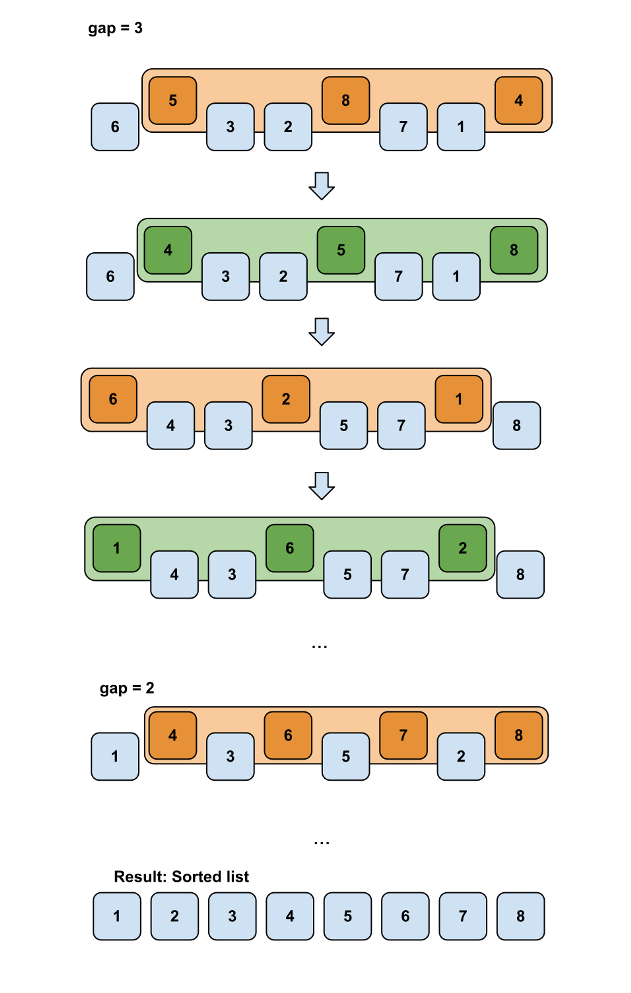
时间复杂度:介于$O(n)$和$O(n^2)$之间。
1 | def shellSort(alist): |
1 | After increments of size 4 The list is [20, 26, 44, 17, 54, 31, 93, 55, 77] |
合并排序
递归地将一个list拆分成两个sublist,然后merge。
时间复杂度是:$O(nlogn)$。
1 | def mergeSort(alist): |
1 | Splitting [54, 26, 93, 17, 77, 31, 44, 55, 20] |
快速排序
递归地执行:小的元素移到pivot左边,大的元素移到pivot的右边。
类比军训时,教官会找出一个同学说,以这位同学为基准,矮的站右边,高的站右边。
一般在实现的时候,上面提到的这步使用双指针的技巧实现。
时间复杂度是:$O(nlogn)$。
1 | def quickSort(alist): |
作业
q1
计算装填因子$λ$分别是:0.1, 0.25, 0.5, 0.75, 0.9, 0.99时需要的比较次数。
计算公式:$\frac{1}{2}(1+\frac{1}{1−λ})$。
直接封装一个函数:
1 | def hash_compare(load_fraction): |
1 | 0.1 : 1.05555555556 |
q2
设计计算字符串的hash值的hash函数。
使用positional weight:

1 | def hash_function_4str(key_str, size): |
1 | 641 |
q4
调研string的hash函数:
参考这篇博客
q9
修改快排中pivot的位置(原算法的pivot是第一个元素,题目推荐尝试中间元素),对比性能。
1 | def quickSort(alist): |
1 | pivotvalue: 77 |
pivot设置在中间位置可以让已经排好序的list不用再做交换操作。