第十章:Sequence Modeling:Recurrent and Recursive Nets
10. Sequence Modeling: Recurrent and Recursive Nets
循环神经网络(Recurrent Neural Network,RNN)
- 是一类用于处理序列数据的神经网络。
-RNN在不同的时间点上共享参数,使得模型能够扩展到不同长度的样本并进行泛化。 - 如果我们在每个时间点都有一个单独的参数,我们不但不能泛化到训练时没有见过序列长度,也不能在时间上共享不同序列长度和不同位置的统计强度。
- $h^{(t)} = f (h^{(t−1)}, x^{(t)} ; θ)$
展开过程的两个主要优点:
- 无论序列的长度,学成的模型始终具有相同的输入大小。
- 可以在每个时间节点使用相同的转移函数$f$。
重要的几种设计模式:
- 1.每个时间步都有输出,并且隐藏单元之间有循环连接的循环网络;
- 2.每个时间步都产生一个输出,只有当前时刻的输出到下个时刻的隐藏单元之间有循环连接的循环网络;
- 3.隐藏单元之间存在循环连接,但读取整个序列后产生单个输出的循环网络。
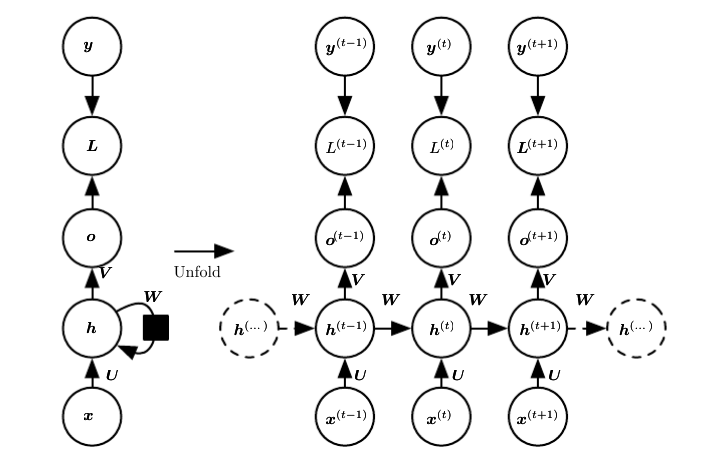
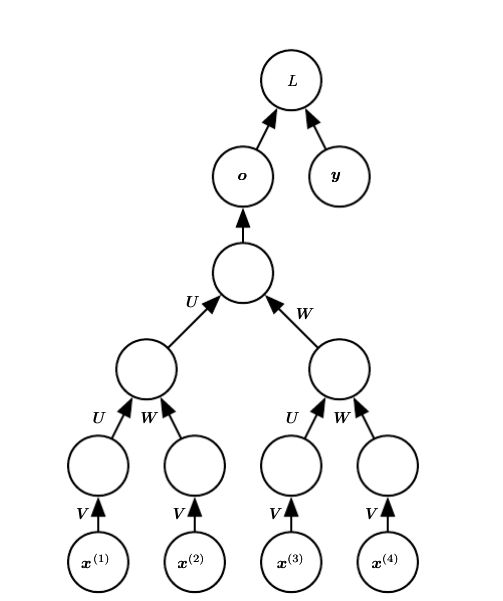
典型的RNN:
- https://raw.githubusercontent.com/applenob/reading_note/master/res/rnn.png
- $a^{(t)}=b+Wh^{(t−1)}+Ux^{(t)}$
- $h^{(t)}=tanh(a^{(t)})$
- $o^{(t)}=c+Vh^{(t)}$
- $y^{(t)}=softmax(o^{(t)})$
- $\theta = {W,U,V,b,c}$,其中,$b,c$是偏置参数向量。
- $L^{(t)}$是给定$x^{(1)}, x^{(2)}, …,
x^{(t)}$后$y^{(t)}$的负似然对数。 - $L({x^{(1)}, x^{(2)}, …, x^{(t)}},{y^{(1)}, y^{(2)}, …, y^{(t)}})\=\sum_t L^{(t)}\=-\sum_tlogp_{model}(y^{(t)}|x^{(1)}, x^{(2)}, …, x^{(t)})$
- 应用于展开图的反向传播算法被称为通过时间反向传播(back-propagation through time, BPTT)。
{kind=link}
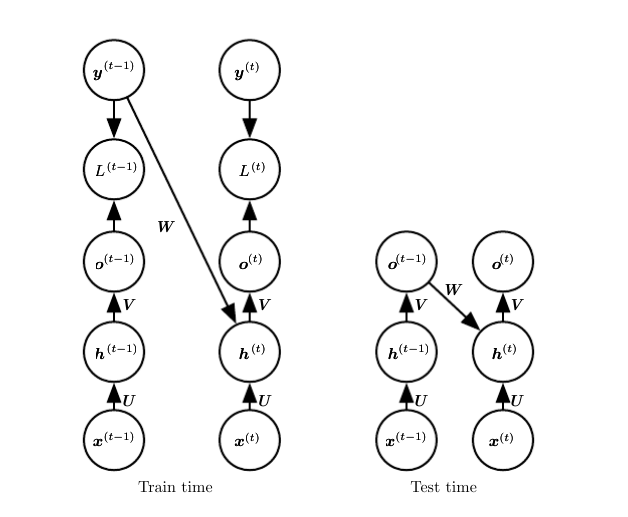
Teacher Forcing
- 每一步的输入包含上一步的输出意味着模型不能并行训练。
- 使用Teacher Forcing训练模型时,使用最大似然准则,而在时刻$t+1$接收真实值$y^{(t)}$作为输入: 条件最大似然准则是:$logp(y^{(1)},y^{(2)}∣x^{(1)},x^{(2)})=logp(y^{(2)}∣y^{(1)},x^{(1)},x^{(2)})+logp(y^{(1)}∣x^{(1)},x^{(2)})$
- https://raw.githubusercontent.com/applenob/reading_note/master/res/teacher-forcing.png
{kind=link}
确定序列的长度的方式
- 1.对于文本类的数据,添加一个对应于序列末端的特殊符号
EOS; - 2.引入一个额外的Bernoulli输出,表示在每个时间步决定继续生成或停止生成,这个方法最通用D;
- 3.将一个额外的输出添加到模型并预测长度$\tau$本身:$P(x^{(1)},…,x^{(τ)})=P(τ)P(x^{(1)},…,x^{(τ)}∣τ)$。
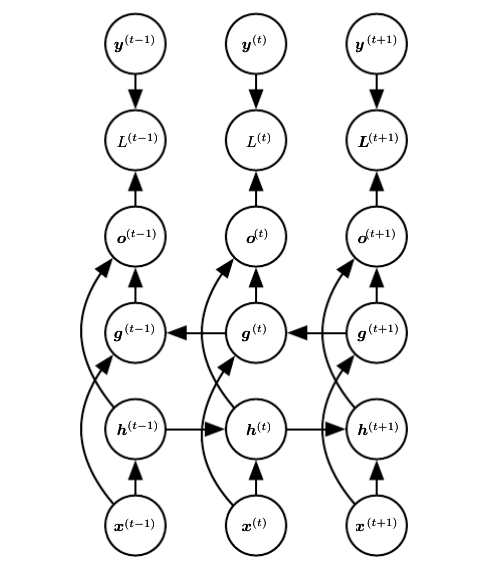
双向RNN(Bidirectional RNNs): - 在许多应用中,我们要输出的$y^{(t)}$的预测可能依赖于整个输入序列,于是有了双向RNN。
- https://raw.githubusercontent.com/applenob/reading_note/master/res/bi-rnn.png
{kind=link}
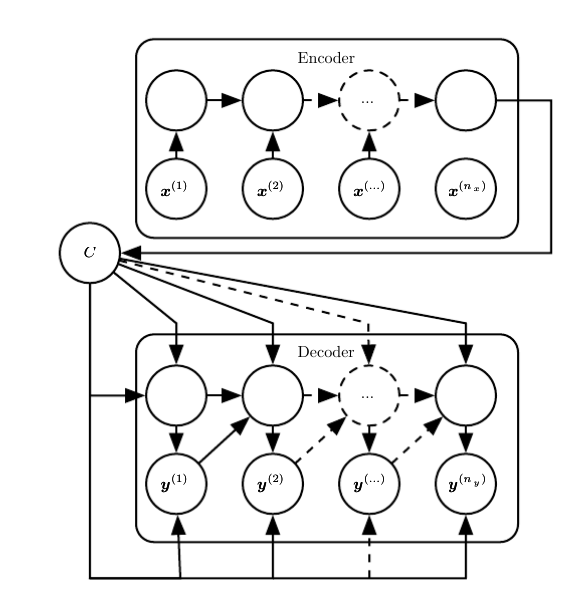
编码-解码架构(Encoder-Decoder):
-在一些应用中,我们需要将输入序列映射到不一定等长的输出序列,于是有了Encoder-Decoder。
- (1)编码器处理输入序列,编码器输出上下文$C$(通常是最终隐藏状态的简单函数)。
- (2)解码器则以固定长度的向量为条件产生输出序列$Y=(y^{(1)},\dots, y^{(n_y)})$。
- https://raw.githubusercontent.com/applenob/reading_note/master/res/en-de.png
{kind=link}
递归神经网络(Recursive Neural Network):
- 它被构造为深的树状结构而不是RNN的链状结构,递归网络已成功地应用于输入是数据结构的神经网络,如自然语言处理和计算机视觉深度。
- 它的一大优势是对于具有相同长度$\tau$的序列,深度(通过非线性操作的组合数量来衡量)可以急剧地从$\tau$减小为$O(\log \tau)$,这可能有助于解决长期依赖。
- https://raw.githubusercontent.com/applenob/reading_note/master/res/recursive-nn.png
{kind=link}
长期依赖的挑战(Long-Term Dependencies):问题描述:经过许多阶段传播后的梯度倾向于消失(大部分情况)或爆炸(很少,但对优化过程影响很大)。
解决方法:
1.回声状态网络(Echo State Networks):
- 从$h^{(t-1)}$到$h^{(t)}$的循环权重映射以及从$x^{(t)}$到$h^{(t)}$的输入权重映射是循环网络中最难学习的参数。
- 避免这种困难的方法是设定循环隐藏单元,使其能很好地捕捉过去输入历史,并且只学习输出权重。
2.多时间尺度的策略:
- 设计工作在多个时间尺度的模型,使模型的某些部分在细粒度时间尺度上操作并能处理小细节,而其他部分在粗时间尺度上操作并能把遥远过去的信息更有效地传递过来。
- 1.时间维度的跳跃连接(skip connection):增加从遥远过去的变量到目前变量的直接连接是得到粗时间尺度的一种方法。
- 2.渗漏单元(Leaky Units):我们对某些$v$值应用更新$\mu^{(t)} \gets \alpha \mu^{(t-1)} + (1-\alpha)v^{(t)}$累积一个滑动平均值$\mu^{(t)}$,其中$\alpha$是一个从$ \mu^{(t-1)}$到$ \mu^{(t)}$线性自连接的例子。
当$\alpha$接近1时,滑动平均值能记住过去很长一段时间的信息,而当$\alpha$接近0,关于过去的信息被迅速丢弃。
线性自连接的隐藏单元可以模拟滑动平均的行为。 这种隐藏单元称为渗漏单元。3.删除连接:主动删除长度为一的连接并用更长的连接替换它们。
3.门控RNN:实际应用中最有效的序列模型,主要有LSTM和GRU。
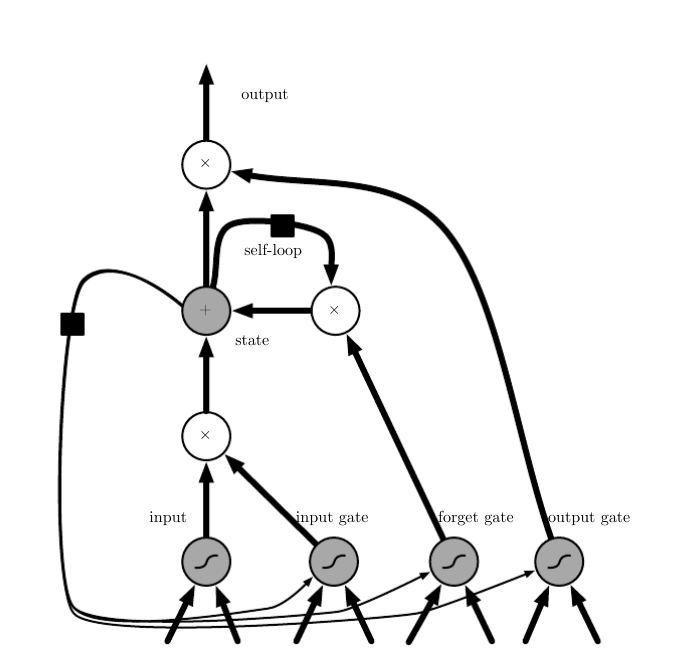
LSTM
- long short-term memory
- 关键思想:**自循环的权重视上下文而定,而不是固定的(普通的RNN是固定的W)。 **
- 所谓的自循环的权重,由遗忘门控制。
- https://raw.githubusercontent.com/applenob/reading_note/master/res/lstm.png
- 遗忘门:$f^{(t)}_i=σ(b^f_i+\sum_jU^f_{i,j}x^{(t)}_j+\sum_jW^f_{i,j}h^{(t−1)}_j)$
- 输入门:$i^{(t)}_i=σ(b_i+∑_jU_{i,j}x^{(t)}_j+∑_jW_{i,j}h^{(t−1)}_j)$
- 外部输入门(备选状态):$g^{(t)}_i=σ(b^g_i+∑_jU^g_{i,j}x^{(t)}_j+∑_jW^g_{i,j}h^{(t−1)}_j)$
- 内部状态:$s^{(t)}_i=f^{(t)}_is^{(t−1)}_i+g^{(t)}_ii^{(t)}_i$
- 输出门:$h^{(t)}_i=tanh(s^{(t)}_i)q^{(t)}$,$q^{(t)}_i=σ(b^o_i+∑_jU^o_{i,j}x^{(t)}_j+∑_jW^o_{i,j}h^{(t−1)}_j)$。
{kind=link}
LSTM vs. RNN and GRU
- LSTM的自循环的权重视上下文而定,而不是固定的;而普通的RNN是固定的W。
- 内部状态:
- RNN:$h^{(t)}=\sigma(b+Wh^{(t−1)}+Ux^{(t)})$
- LSTM:$s^{(t)}_i=f^{(t)}_is^{(t−1)}_i+g^{(t)}_ii^{(t)}_i$,$g^{(t)}_i$又称为“备选状态”。
- GRU:$h^{(t)}_i=u^{(t−1)}_ih^{(t−1)}_i+(1−u^{(t−1)}_i)\tilde h_t$
- 传统的RNN使用“覆写”的方式计算状态:$S_t=f(S_{t-1},x_t)$,根据求导的链式法则,这种形式直接导致梯度别表示成连积的形式,容易导致梯度消失或者梯度爆炸。
- 现代的RNN(包括但不限于LSTM单元),使用“累加”的方式计算状态:$S_t = \sum_{\tau=1}^t\Delta S_{\tau}$,这种累加形式导致导数也是累加的形式,因此避免了梯度的消失。
GRUs
- 与LSTM的主要区别是:单个门控单元同时控制遗忘因子和更新状态单元的决定。
- 备选状态:$\tilde h_t =σ(b_i+∑_jU_{i,j}x^{(t)}_j+∑_jW_{i,j}r^{(t−1)}_jh^{(t−1)}_j)$
- $h^{(t)}_i=u^{(t−1)}_ih^{(t−1)}_i+(1−u^{(t−1)}_i)\tilde h_t$
- 更新门:$u^{(t)}_i=σ(b^u_i+∑_jU^u_{i,j}x^{(t)}_j+∑_jW^u_{i,j}h^{(t)}_j)$
- 复位门:$r^{(t)}_i=σ(b^r_i+∑_jU^r_{i,j}x^{(t)}_j+∑_jW^r_{i,j}h^{(t)}_j)$
截断梯度(Clipping Gradients):
- 强非线性函数(如由许多时间步计算的循环网络)往往倾向于非常大或非常小幅度的梯度。
-目标函数(作为参数的函数)存在一个伴随”悬崖”的”地形”:宽且相当平坦区域被目标函数变化快的小区域隔开,形成了一种悬崖。 - 我们通常使用衰减速度足够慢的学习率,使连续的步骤具有大致相同的学习率。
截断梯度是一个简单的解决方案:在参数更新之前截断梯度$g$的范数$||g||$:$if;||g||>v:;;
g←\frac{gv}{||g||}$,其中$v$是参数梯度的阈值,是一个标量。
- 可以解决梯度爆炸问题。