第三章:Probability and Information Theory
3. Probability and Information Theory
概率论部分
频率学派概率(frequentist probability):认为概率和事件发生的频率相关。
贝叶斯学派概率(Bayesian probability):认为概率是的对某件事发生的确定程度,可以理解成是确信的程度(degree of belief)。
随机变量(random variable):一个可能随机获取不同值的变量。
概率质量函数(probability mass function,PMF):用来描述离散随机变量的概率分布。表示为P(x),是状态到概率的映射。
概率密度函数(probability density function,PDF):用来描述连续随机变量的概率分布,p(x)。
条件概率(conditional probability):$P(y=y|x=x) = \frac{P(y=y, x=x)}{P(x=x)}$
条件概率的链式法则(chain rule of conditional probability):$P(x^{(1)}, …, x^{(n)}) =
P(x^{(1)})\prod^n_{i=2}P(x^{(i)}|x^{(1)}, …, x^{(i-1)})$
独立(independence):$\forall x \in x, y ∈ y, p(x=x, y=y) = p(x=x)p(y=y)$
条件独立(conditional independence):$\forall x ∈ x, y ∈ y, z ∈ z,p(x=x, y=y |
z=z) = p(x=x | z=z)p(y=y | z=z)$
期望(expectation):
- 期望针对某个函数$f(x)$,关于概率分布$P(x)$的平均值。
- 对离散随机变量:$E_{x \sim P}[f(x)] = \sum_xP(x)f(x)$
- 对连续随机变量:$E_{x \sim p}[f(x)] = \int P(x)f(x)dx$
- 期望是线性的:$E_x[αf(x)+βg(x)] =
αE_x[f(x)]+βE_x[f(x)]$
方差(variance):
- 用来衡量从随机变量$x$的分布函数$f(x)$中采样出来的一系列值和期望的偏差。
- $Var(x) =
E[(f(x)-E[f(x)])^2]$,方差开平方即为标准差(standard deviation)。
协方差(covariance):
- 用于衡量两组值之间的线性相关程度。
- $Cov(f(x), g(y)) = E[(f(x)-E[f(x)])(g(y)-E[g(y)])]$。
- 独立比协方差为0更强,因为独立还排除了非线性的相关。
贝努力分布(Bernoulli Distribution):随机变量只有两种可能的分布,只有一个参数:$Φ$,即$x=1$的概率。
多项式分布(Multinoulli Distribution)随机变量有$k$种可能的分布,参数是一个长度为$k-1$的向量$p$。
高斯分布(Gaussian Distribution)
- 即正态分布(normal distribution)
- $\textit{N}(x;μ,σ^2) = \sqrt{\frac{1}{2πσ^2}}exp(-\frac{1}{2σ^2}(x-μ)^2)$。
- 中心极限定理(central limit theorem)认为,大量的独立随机变量的和近似于一个高斯分布,这一点可以大量使用在应用中,我们可以认为噪声是属于正态分布的。
- https://raw.githubusercontent.com/applenob/reading_note/master/res/gauss.PNG
多元正态分布(multivariate normal distribution): - 给定协方差矩阵$\mathbf{Σ}$(正定对称),$\textit{N}(x;μ,Σ) = \sqrt{\frac{1}{(2π)^ndet(Σ)}}exp(-\frac{1}{2}(x-μ)^TΣ^{-1}(x-μ))$
- https://upload.wikimedia.org/wikipedia/commons/thumb/8/8e/MultivariateNormal.png/450px-MultivariateNormal.png
{kind=link}
{kind=link}
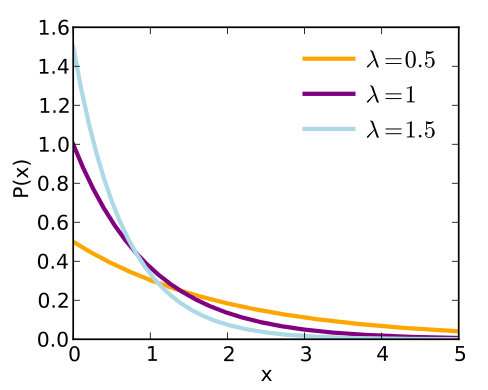
指数分布(exponential distribution):
在深度学习的有研究中,经常会用到在x=0点获得最高的概率的分布,$p(x; λ) = λ\mathbf{1}_{x≥0}exp(-λx)$,或者:若$x≥0$则$f(x) = λexp(-λx)$;否则为0。
其中λ > 0是分布的一个参数,常被称为率参数(rate parameter)。
https://raw.githubusercontent.com/applenob/reading_note/master/res/exp_dis.png
{kind=link}
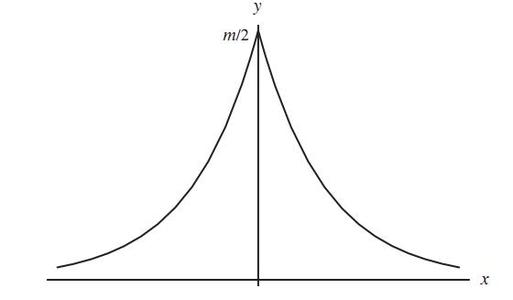
拉普拉斯分布(Laplace Distribution):
- 另一个可以在一个点获得比较高的概率的分布。
- $Laplace(x ;μ,γ) = \frac{1}{2γ}exp(-\frac{|x-μ|}{γ})$
- https://raw.githubusercontent.com/applenob/reading_note/master/res/laplace.jpg
{kind=link}
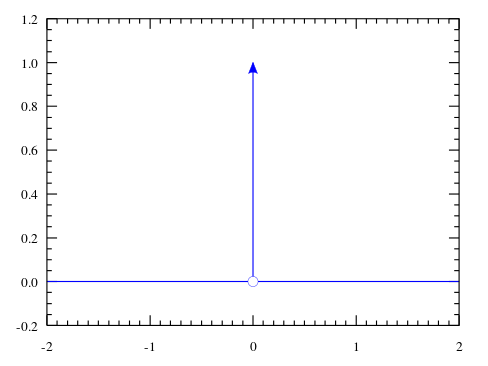
迪拉克分布(Dirac Distribution):
- $p(x) = δ(x-μ)$,这是一个泛函数。迪拉克分布经常被用于组成经验分布(empirical distribution)
- $p(x) = \frac{1}{m}\sum_{i=1}^m{δ(x-x^{(i)})}$
- https://raw.githubusercontent.com/applenob/reading_note/master/res/dirac.png
{kind=link}
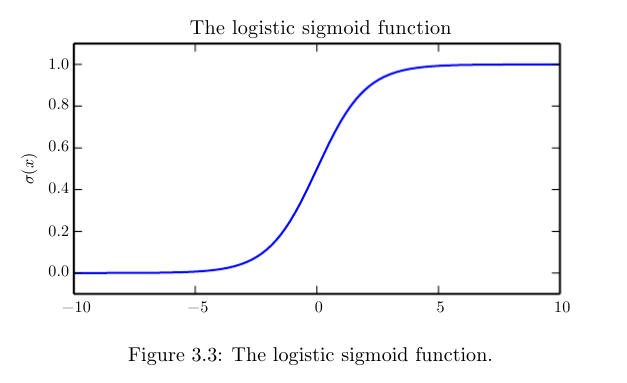
逻辑斯蒂函数(logistic function):
- $σ(x) = \frac{1}{1+exp(-x)}$,常用来生成贝努力分布的Φ参数。
- https://raw.githubusercontent.com/applenob/reading_note/master/res/logistic.png
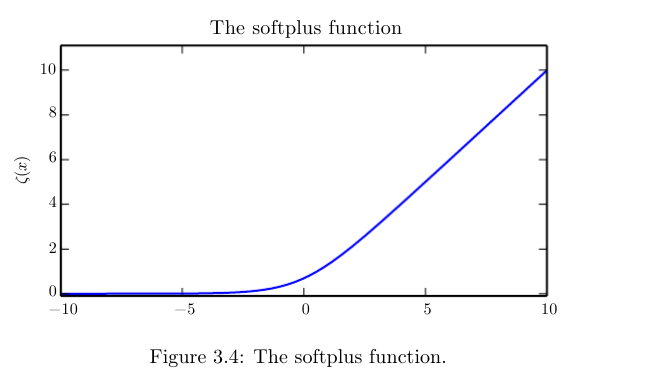
softplus function: - $ζ(x) = log(1+exp(x))$,是“取正”函数的“soft”版
- $x^+ = max(0, x)$
- https://raw.githubusercontent.com/applenob/reading_note/master/res/softplus.png
贝叶斯公式(Bayes’ Rule):$P(x|y) = \frac{P(x)P(y|x)}{P(y)}$
{kind=link}
{kind=link}
信息论部分
信息论背后的直觉:学习一件不太可能的事件比学习一件比较可能的事件更有信息量。
信息(information)需要满足的三个条件:
- 1.比较可能发生的事件的信息量要少;
- 2.比较不可能发生的事件的信息量要大;
- 3.独立发生的事件之间的信息量应该是可以叠加的。
自信息(Self-Information):对事件$x=x$,$I(x) = -logP(x)$,满足上面三个条件,单位是nats(底为e)
香农熵(Shannon Entropy):
- 自信息只包含一个事件的信息。
- **对于整个概率分布$p(x)$**,不确定性可以这样衡量:$E_{x\sim P}[I(x)] = -E_{x\sim P}[logP(x)]$。
- 也可以表示成$H(P)$。
多个随机变量:
1.联合熵(Joint Entropy):$H(X,Y)=-∑_{x,y}p(x,y)log(p(x,y))$,同时考虑多个事件的条件下(即考虑联合分布概率)的熵。
2.条件熵(Conditional Entropy):$H(X|Y)=-∑_yp(y)∑_xp(x|y)log(p(x|y))$,某件事情已经发生的情况下,另外一件事情的熵。
3.互信息(Mutual Information):$I(X,Y)=H(X)+H(Y)−H(X,Y)$,两个事件的信息相交的部分。
4.信息变差(Variation of information):$V(X,Y)=H(X,Y)−I(X,Y)$,两个事件的信息不相交的部分。
KL散度(Kullback-Leibler Divergence):
- 衡量两个分布$P(x)$和$Q(x)$之间的差距。
- $D_{KL}(P||Q)=E_{x\sim P}[log \frac{P(x)}{Q(x)}]=E_{x\sim P}[logP(x)-logQ(x)]$,注意$D_{KL}(P||Q)≠D_{KL}(Q||P)$
交叉熵(Cross Entropy):
- $H(P,Q)=H(P)+D_{KL}(P||Q)=-E_{x\sim P}[logQ(x)]$
- 假设$P$是真实分布,$Q$是模型分布,那么最小化交叉熵$H(P,Q)$可以让模型分布逼近真实分布。
注:信息论部分很好的参考资料,colah的博客。
图模型(Structured Probabilistic Models)
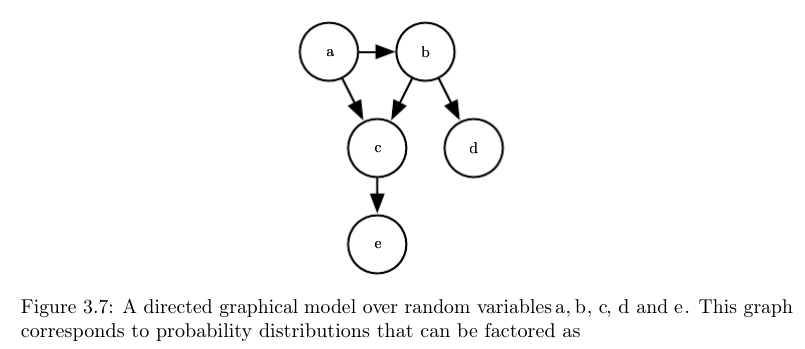
有向图模型(Directed Model):
- $p(x) = \prod_i p(x_i | Pa_g(x_i))$, 其中$Pa_g(x_i)$是$x_i$的父节点。
- https://raw.githubusercontent.com/applenob/reading_note/master/res/dg.png
- $P(a,b,c,d,e)=p(a)p(b|a)p(c|a,b)p(d|b)p(e|c)$
{kind=link}
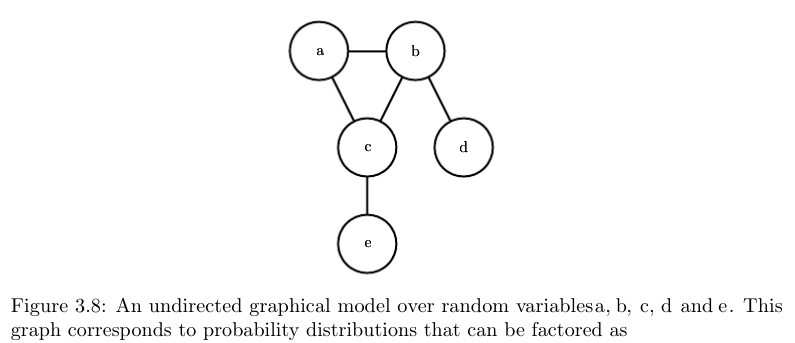
无向图模型(Undirected Model):
- 所有节点都彼此联通的集合称作“团”(Clique)。
- $p(x)=\frac{1}{Z}\prod_i{Φ^{(i)}(C^{(i)})}$,其中,Φ称作facor,每个factor和一个团(clique)相对应。
- https://raw.githubusercontent.com/applenob/reading_note/master/res/udg.png
- $p(a,b,c,d,e) = \frac{1}{Z}Φ^{(1)}(a,b,c)Φ^{(2)}(b,d)Φ^{(3)}(c,e)$
{kind=link}