第七章:Regularization for Deep Learning
7. Regularization for Deep Learning
正则化(Regularization):对学习算法的修改——旨在减少泛化误差而不是训练误差。
参数范数惩罚(Parameter Norm Penalties):通过对目标函数J添加一个**参数范数惩罚Ω(θ)**,来限制模型的学习能力。
我们将正则化后的目标函数记为$\tilde{J}$:$\tilde{J}(θ;X,y)=J(θ;X,y)+αΩ(θ)$,其中α∈[0,∞)是权衡范数惩罚项Ω和标准目标函数J(X;θ)相对贡献的超参数。说明,在神经网络中我们通常只对每一层仿射变换的权重w做惩罚而不对偏置做正则惩罚。典型的参数范数惩罚有$L^2$参数正则和$L^1$参数正则。
$L^2$参数正则($L^2$ Parameter Regularization):也就是权重衰减(weight decay),顾名思义,权重会有所减小;罚项为$Ω(θ)=\frac{1}{2}||w||_2^2$,也称为岭回归(ridge regression)或Tikhonov正则。
在训练过程中,只有在显著减小目标函数方向上的参数会保留得相对完好;在无助于目标函数减小的方向(对应Hessian矩阵较小的特征值)上改变参数不会显著增加梯度。
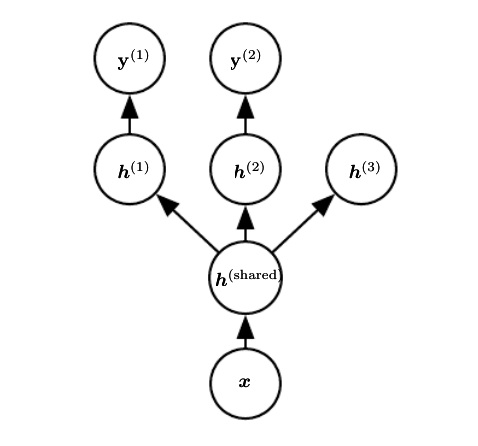
这种不重要方向对应的分量会在训练过程中因正则化而衰减掉。
$L^1$参数正则($L^1$ Parameter Regularization):罚项为$Ω(θ)=||w||_1=\sum_i|w_i|$,相比于$L^2$正则,$L^1$正则产生更多的稀疏性结果,此处稀疏性指的是最优值中的一些参数为0。这一性质也使得$L^1$正则在特征选择机制中被广泛使用。
作为约束的范数惩罚:我们可以把参数范数惩罚看作对权重强加的约束。 如果Ω是$L^2$范数,那么权重就是被约束在一个$L^2$球中。
如果Ω是$L^1$范数,那么权重就是被约束在一个$L^1$范数限制的区域中。
数据集增强(Dataset Augmentation):实际上,让机器学习模型泛化得更好的最好办法是使用更多的数据进行训练。 但在实践中,我们拥有的数据量是很有限的。
解决这个问题的一种方法是创建假数据并添加到训练集中。这种方法用在分类任务来说是很简单的; 但这种方法对于其他许多任务来说并不那么容易,比如密度估计问题。
数据集增强在目标识别(objective recognition)和语音识别(speech recognition)上被证实比较有效。通常情况下,人工设计的数据集增强方案可以大大减少机器学习技术的泛化误差。
噪声鲁棒性(Noise Robustness):噪声可以直接注入到输入数据,作为数据集增强,向输入添加方差极小的噪声等价于对权重施加范数惩罚;也可以向隐藏单元添加噪声,这种罚项更加强大;可以直接向权重w注入噪声,经常用于rnn,它推动模型进入对权重小的变化相对不敏感的区域,找到的点不只是极小点,还是由平坦区域所包围的最小点;还可以向输出目标注入噪声,比如label smoothing。
半监督学习(Semi-Supervised Learning):在深度学习的背景下,半监督学习通常指的是学习一个表示:h=f(x)。 学习表示的目的是使相同类中的样本有类似的表示。
多任务学习(Multi-Task Learning):通过合并几个任务中的样例(可以视为对参数施加的软约束)来提高泛化的一种方式。
当模型的一部分在任务之间共享时,模型的这一部分更多地被约束为良好的值(假设共享是合理的),往往能更好地泛化。从深度学习的观点看,底层的先验知识如下:能解释数据变化的因素中,某些因素是跨两个或更多任务共享的。
https://raw.githubusercontent.com/applenob/reading_note/master/res/multi-task.png
{kind=link}
提前停止(Early Stopping):我们经常观察到,训练误差会随着时间的推移逐渐降低,但验证集的误差会再次上升。这意味着,如果在验证集误差开始上升的时候提前停止训练,这就是“提前终止”策略。可以获得更好的模型可能是深度学习中最常用的正则化形式。 它的流行主要是因为有效性和简单性,还可以减少训练过程的计算成本。
参数绑定(Parameter Tying):A模型和已经有参数的模型B任务相似,可以让A尽可能接近B,设置罚项:$Ω(w^{(A)},w^{(B)})=‖w^{(A)}−w^{(B)}‖^2_2$
参数共享(Parameter Sharing):直接让A模型的参数等于B模型的参数,典型的应用是CNN。
稀疏表示(Sparse Representation):惩罚神经网络中的激活单元,稀疏化激活单元,惩罚项:Ω(h)。稀疏表示和$L^1$正则带来的稀疏参数容易混淆,区别:
稀疏表示:https://raw.githubusercontent.com/applenob/reading_note/master/res/sparse-rep.png
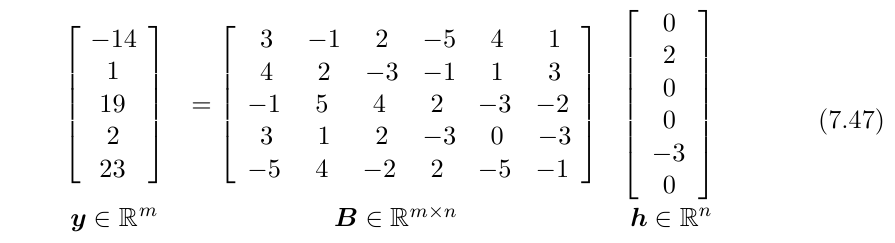{kind=link}
稀疏参数:https://raw.githubusercontent.com/applenob/reading_note/master/res/sparse-weight.png
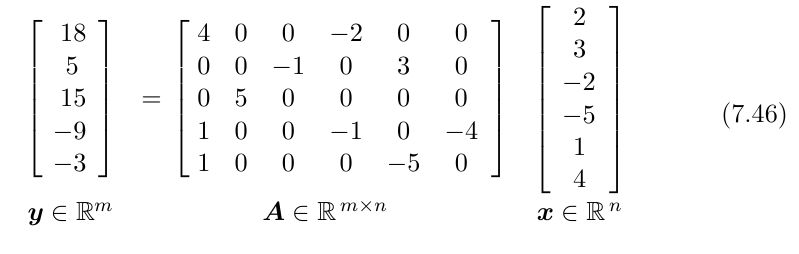{kind=link}
Bagging(Bootstrap Aggregating):通过结合多个模型来降低泛化误差。这种方法通常又被称为“集成方法”(Ensemble Method)。具体来说,Bagging涉及构造k个不同的数据集,再训练k个模型,集合所有模型的预测结果投票得出最后结果。模型平均是一个减少泛化误差的非常强大可靠的方法。
但在作为科学论文算法的基准时,它通常是不鼓励使用的,因为任何机器学习算法都可以从模型平均中大幅获益。
Dropout:Dropout可以被认为是集成大量深层神经网络的实用Bagging方法。 但是Dropout训练与Bagging训练不太一样。
在Bagging的情况下,所有模型都是独立的。 在Dropout的情况下,所有模型共享参数。 Dropout不仅仅是训练一个Bagging的集成模型,并且是共享隐藏单元的集成模型。 这意味着无论其他隐藏单元是否在模型中,每个隐藏单元必须都能够表现良好。 隐藏单元必须准备好进行模型之间的交换和互换。
因此Dropout正则化每个隐藏单元不仅是一个很好的特征,更要在许多情况下是良好的特征。
除此之外,计算方便是Dropout的一个优点,Dropout的另一个显著优点是不怎么限制适用的模型或训练过程。
然而,当只有极少的训练样本可用时,Dropout不会很有效。
对抗训练(Adversarial Training):
对抗训练通过鼓励网络在训练数据附近的局部区域恒定来限制这一高度敏感的局部线性行为。 这可以被看作是一种明确地向监督神经网络引入局部恒定先验的方法。