第九章:Convolutional Networks
9. Convolutional Networks
卷积网络(Convolutional Networks):卷积网络是指那些至少在网络的一层中使用卷积运算来替代一般的矩阵乘法运算的神经网络。
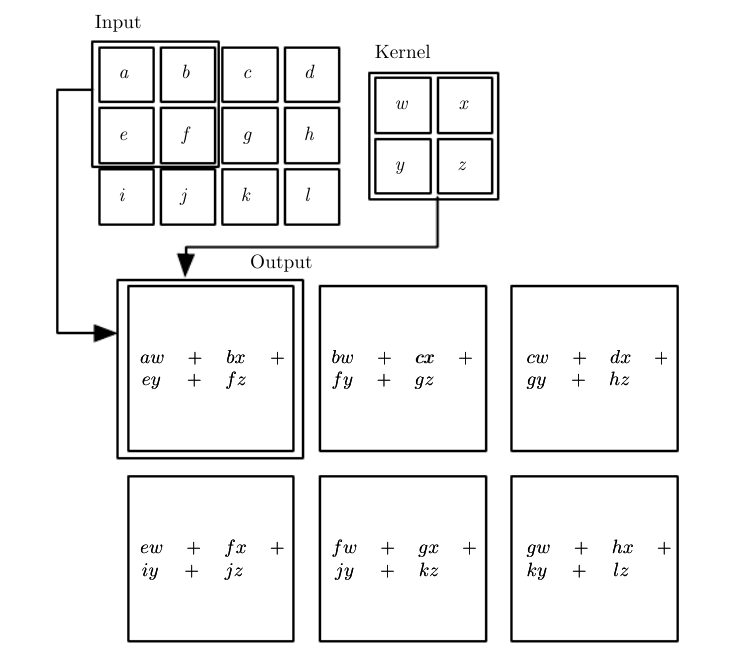
卷积(Convolution)操作
- 卷积是一种特殊的线性运算。
- 假设我们正在用激光传感器追踪一艘宇宙飞船的位置,$x(t)$表示宇宙飞船在时刻t的位置,$x$和$t$都是实值。
- 假设我们的传感器受到一定程度的噪声干扰。 为了得到飞船位置的低噪声估计,我们对得到的测量结果进行平均。
- 显然,时间上越近的测量结果越相关,所以我们采用一种加权平均的方法,对于最近的测量结果赋予更高的权重。
采用一个加权函数$w(a)$来实现,其中a表示某个测量的测量时刻:$s(t)=∫x(a)w(t−a)da$,或者用离散的表达式:$s(t)=(x∗w)(t)=∑_{a=−∞}^∞x(a)w(t−a)$。 - 这就是卷积操作,可以用星号表示:$s(t)=(x∗w)(t)$。
- $x$是输入(input);$w$是核(kernel);输出的$s$是特征映射(feature map)。
互相关函数(cross-correlation):
- 卷积操作在kernel中的变量是$t-a$,这保证了卷积操作是可交换的(commutative)。
- 许多神经网络库会实现一个相关的函数,称为互相关函数,和卷积运算几乎一样但是并没有对核进行翻转:$s(t)=∫x(a)w(a)da$。
- https://raw.githubusercontent.com/applenob/reading_note/master/res/conv.png
{kind=link}
卷积运算改进机器学习系统的动机
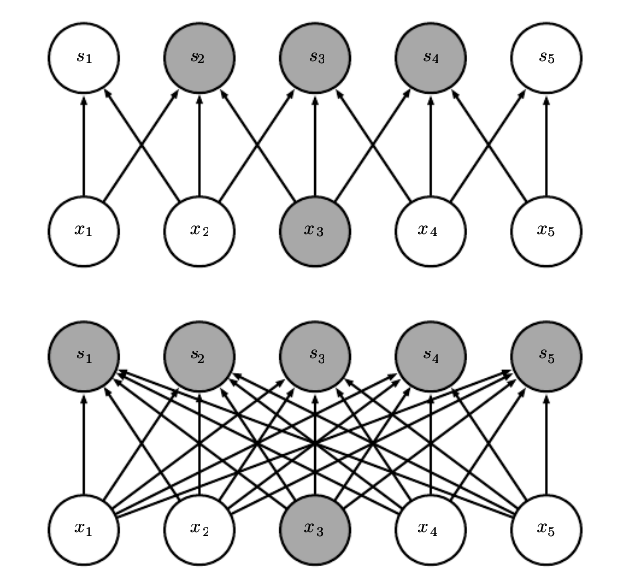
1.稀疏交互(Sparse Interaction):
- 传统的神经网络使用矩阵乘法来建立输入与输出的连接关系,每一个输出单元与每一个输入单元都产生交互。
- 卷积网络具有稀疏交互(也叫做稀疏连接或者稀疏权重)的特征,这是使核的大小远小于输入的大小来达到的。
- 如果有$m$个输入和$n$个输出,那么矩阵乘法需要m×n个参数并且相应算法的时间复杂度为$O(m×n)$。
- 如果我们限制每一个输出拥有的连接数为k,那么稀疏的连接方法只需要$k×n$个参数以及$O(k×n)$的运行时间。
- 在很多实际应用中,只需保持$k$比$m$小几个数量级,就能在机器学习的任务中取得好的表现。
- https://raw.githubusercontent.com/applenob/reading_note/master/res/sparse.png
{kind=link}
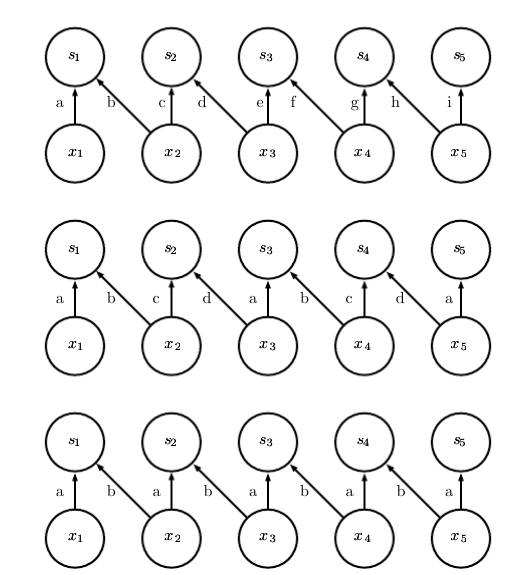
2.参数共享(Parameter Sharing):
- 参数共享是指在一个模型的多个函数中使用相同的参数。
- 在卷积神经网络中,核的每一个元素都作用在输入的每一位置上。
- 卷积在存储需求和统计效率方面极大地优于稠密矩阵的乘法运算。
3.等变表示(Equivariant Representation):
- 参数共享的特殊形式使得神经网络层具有对平移等变的性质。
- 函数$f(x)$与$g(x)$满足$f(g(x))=g(f(x))$,就说$f(x)$对于变换$g$具有等变性(equivariant)。
池化(pooling):
- 池化函数使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。
- 例如,最大池化函数(max pooling)给出相邻矩形区域内的最大值。
- 其他常用的池化函数包括相邻矩形区域内的平均值、L2范数以及基于据中心像素距离的加权平均函数。
- 不管采用什么样的池化函数,当输入作出少量平移时,池化能够帮助输入的表示近似不变。
- 对于平移的不变性是指当我们对输入进行少量平移时,经过池化函数后的大多数输出并不会发生改变。
- 局部平移不变性是一个很有用的性质,尤其是当我们关心某个特征_是否出现_而不关心它出现的具体位置时。
卷积与池化作为一种无限强的先验:
- 先验的强或者弱取决于先验中概率密度的集中程度:弱先验具有较高的熵值,例如方差很大的高斯分,这样的先验允许数据对于参数的改变具有或多或少的自由性。
- 强先验具有较低的熵值,例如方差很小的高斯分布,这样的先验在决定参数最终取值时起着更加积极的作用。
- 一个无限强的先验需要对一些参数的概率置零并且完全禁止对这些参数赋值,无论数据对于这些参数的值给出了多大的支持。
- 因此,我们可以把卷积的使用当作是对网络中一层的参数引入了一个无限强的先验概率分布。
- 这样做带来的一个关键的洞察是卷积和池化可能导致欠拟合;另一个关键洞察是当我们比较卷积模型的统计学习表现时,只能与其他卷积模型做比较。
深度学习框架下的卷积
- 1.通常指由多个并行卷积组成的运算,可以在多个位置提取多种类型的特征。
- 2.输入通常也不仅仅是实值的网格,而是由一系列向量的网格,$Z_{i,j,k}=∑_{l,m,n}V_{l,j+m−1,k+n−1}K_{i,l,m,n}$。
- 3.使用stride,跳过核中的一些位置来降低计算的开销,$Z_{i,j,k}=∑_{l,m,n}[V_{l,(j-1)×s+m,(k-1)×s+n}K_{i,l,m,n}]$。
- 4.对输入用零进行填充(zero-padding)使得它加宽。
- 其中,valid convolution代表不使用padding,输入尺寸是$m$,输出为$m-k+1$;same convolution代表增加padding使得输出尺寸和输入相同都为$m$;full convolution代表增加padding,使得输出尺寸为$m+k-1$。
其他卷积函数变体:
- https://raw.githubusercontent.com/applenob/reading_note/master/res/other-conv.png
- 局部连接网络层(locally connected layers):$Z_{i,j,k}=∑_{l,m,n}[V_{l,j+m−1,k+n−1}w_{i,j,k,l,m,n}]$。
- 平铺卷积(tiled convolution):平铺卷积对卷积层和局部连接层进行了折衷。$Z_{i,j,k}=\sum_{l,m,n}V_{l,j+m−1,k+n−1}K_{i,l,m,n,j\%t+1,k\% t+1}$
{kind=link}
卷积网络的训练:
- 假设我们想要训练这样一个卷积网络:它包含步幅为s的步幅卷积,该卷积的核为K,作用于多通道的图像V,定义为$c(K,V,s)$。
- 假设我们想要最小化某个损失函数$J(V,K)$。
- 在前向传播过程中,我们需要用c本身来输出Z,然后Z传递到网络的其余部分并且被用来计算损失函数J。
- 在反向传播过程中,我们会得到一个张量G满足:$G_{i,j,k}=\frac{∂}{∂Z_{i,j,k}}J(V,K)$。
- 核参数的更新规则:$\frac{∂}{∂K_{i, j, k, l}} J(V, K) = \sum_{m, n} G_{i, m, n} V_{j, (m-1)× s+k, (n-1)× s+l}$。
卷积网络的神经科学基础:
- 卷积网络也许是生物学启发人工智能的最为成功的案例。
- 神经生理学家David Hubel和Torsten Wiesel观察了猫的脑内神经元如何响应投影在猫前面屏幕上精确位置的图像。
- 他们的伟大发现是:处于视觉系统较为前面的神经元对非常特定的光模式(例如精确定向的条纹)反应最强烈,但对其他模式几乎完全没有反应。