任务型对话系统综述
资料
综述类
- A Survey of Task-oriented Dialogue Systems Kaixiang Mo (2017)
- Neural Approaches to Conversational AI (2018)
- 柳泽明学长的对话系统专栏(2018)
- A Survey on Dialogue Systems: Recent Advances and New Frontiers(2017)
- Deep Learning for Dialogue Systems (2017,台湾国立PPT)
- Conversational Agents (Stanford PPT)
- Statistical Methods for Spoken Dialogue Management, chapter 02 (2013)
- 徐阿衡NLP笔记 - 多轮对话之对话管理(Dialog Management) (2018)
科普类
SIGDIAL
- Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue 2018
- Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue 2017
Pipeline
如果把对话系统比作计算机的话,SLU相当于输入,NLG相当于输出设备,而DM相当于CPU(运算器+控制器)。
所谓Pipeline就是将对话系统模块化。每个模块实现一定的功能,将问题逐个击破。
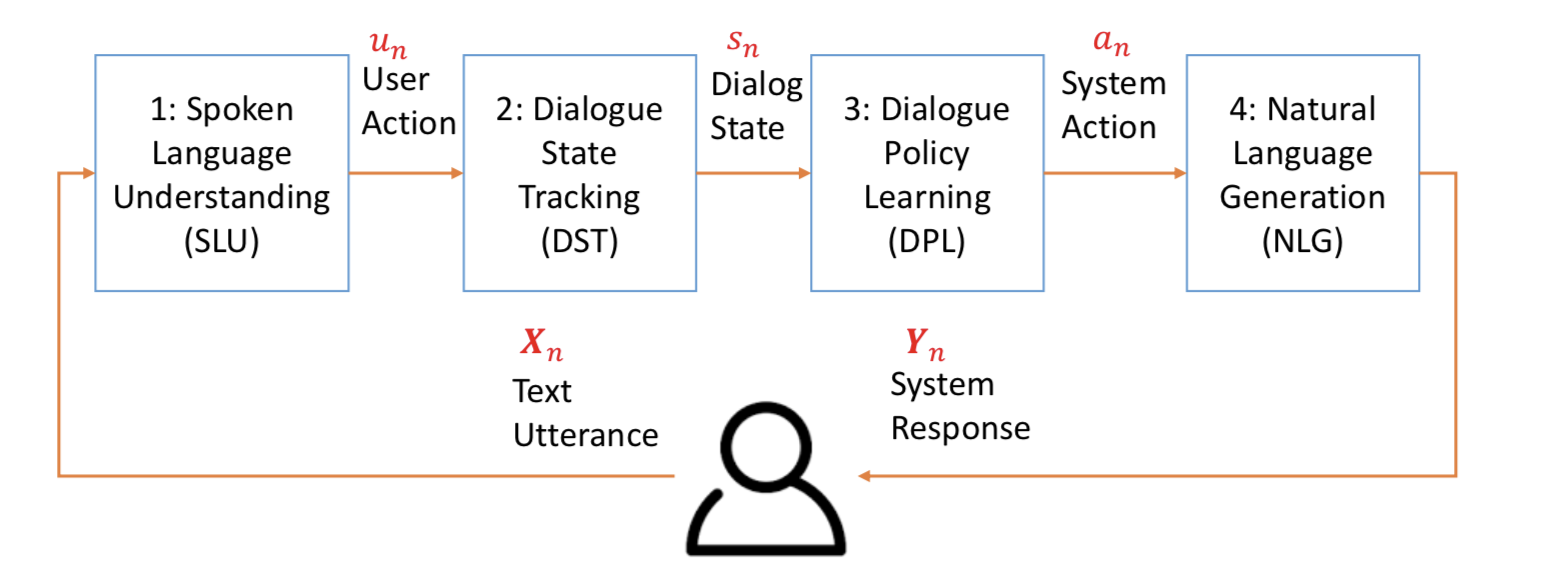
pipeline框架的缺点:
- 1.下游用户的反馈很难反馈到上游某个模块;
- 2.模块间的相互依赖:如果修改某个模块,相关的模块也需要修改。
NLU
NLU即Natural Language Understanding,负责理解用户的语句输入,一般是做意图识别(intent detection)和槽位抽取(slots filling)。
开源代码
- rasa_nlu:Open source library for natural language understanding and machine learning-based dialogue management. - All things around intent classification, entity extraction and action predictions - DIY NLP and chatbot framwork. https://rasa.com/docs/
- Rasa_NLU_Chi:Turn Chinese natural language into structured data 中文自然语言理解。
工具
- pyltp :
pyltp是LTP的 Python 封装,提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注的功能。
资料
- Spoken language understanding from unaligned data using discriminative classification models, ICAPP 2009
*pdf - Onenet: Joint domain, intent, slot prediction for spoken language understanding, ASRU 2017
*pdf
Dialogue Manager
对话管理(Dialogue Manager),通常包括DST(对话状态的追踪,Dialogue State Track)以及DPL(对话策略的学习,Dialogue Policy Learning)。
dialogue management的种类(从简单到复杂):
- Switch statement: 即简单定义一些query模板对应的response。缺点:总是用户拥有主动权,机器不会主动问。也没有使用对话上下文信息。
- Finite state machine:相对强大很多,可以覆盖大部分的对话。缺点:灵活性比较差,必须按照状态机规定的按部就班;相对复杂的对话,有限状态机的构图可能会变得很难维护。
- Goal based:考虑用户每次对话的最终目标(goal),比如订餐馆、设定导航等。比如当机器人收到用户关于餐馆的问题时,可以设定intent是looking_for_restaurant,goal是finding_restaurant。然后机器人可以知道要完成这个goal,需要用户再提供哪些信息,后续就可以去询问关于这些信息的问题。缺点:构建难度相对较大,开源工具少。
- Belief based:前提是:现实中NLU模块不可能完全正确。因此dm需要考虑把信念(概率分布)加进来。
Rule Based
基于规则的方法虽然可以较好利用先验知识从而可以较好解决冷启动等问题,但是需要太多人工、非常不灵活、扩展性和移植性很差、不能同时追踪多种状态。
- 优点:准确、可以实现基于配置的可扩展。
- 缺点:难以真正扩展,复杂场景的代码可能非常复杂。
资料:
- A form-based dialogue manager for spoken language applications. (1996)
- Web-style ranking and SLU combination for dialog state tracking (2014)
基于FSM
FSM(有限状态机,finite state machine)
简单地考虑点和边表示的内容,可以分成两种:
- 1.点表示数据;边表示操作;
- 2.点表示操作;边表示数据。
开源项目
- transitions:A lightweight, object-oriented finite state machine implementation in Python https://github.com/pytransitions/transitions
- Dialogue management using Finite State Models (2002): http://www.coli.uni-saarland.de/~korbay/Courses/DM-SS02/DM-slides/hagen-fsm-slides.pdf
DST
对话状态追踪(Dialogue State Tracker),用于记录和表示当前对话状态。
- 输入:各种可以获取的信息,包括所有的用户utterance、NLU结果、系统动作、以及外部知识库。
- 输出:当前对话的状态评估
s。
由于ASR、SLU等组件的识别结果往往会出错,所以常常会输出N-best列表(带置信度概率),这就要求DST拥有比较强的鲁棒性。所以DST往往输出各个状态的概率分布,b(s)。
状态表示
对话状态表示(DST-State Representation)通常由以下3部分组成:
- 1.目前为止的槽位填充情况。
- 2.本轮对话过程中的用户动作。
- 3.对话历史。
其中,槽位的填充情况通常是最重要的状态表示指标。

根据DST对NLU输出信息的保留程度,状态维护又分两种形式:
- 1-Best:只保留NLU结果中置信度最高的槽位,维护对话状态时,只需等同于槽位数量的空间(k)。
- N-Best: 保留每个槽位NLU结果中N-best的结果,还要维护一个槽位组合在一起的整体(overall)置信度。
状态表示的简化
理论上完整的状态表示,需要维护的状态数是:所有slot的所有可能值的的累乘。因为所有slot搭配都有可能出现。
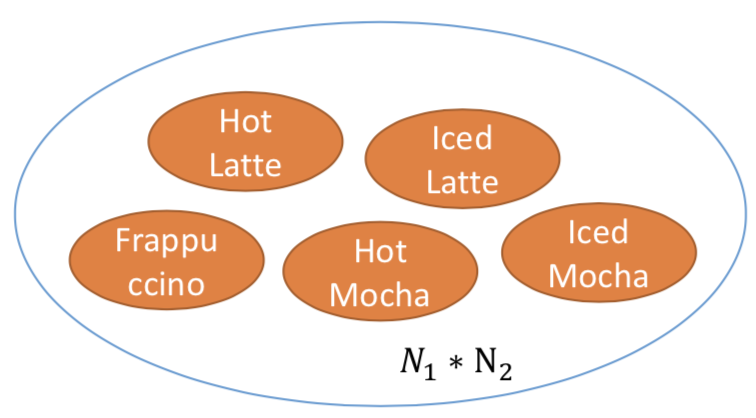
举例:咖啡种类是N1种,即3种,包括Frappuccino(默认是冰的)、Latte、Mocha。温度N2种,即梁两种:Iced、Hot。因此这里需要维护的状态总数是2*3=6。
下面是两种简化:
隐藏信息状态模型 Hidden Information State Model (HIS)
类似于决策树,决策树是对特征空间的切割;HIS是对状态空间的切割。每轮对话,当前空间切分成两个partition。最后需要维护的个数是2的n次方个(切割后空间partition的个数)。处在同一个partition里的状态默认概率相同。
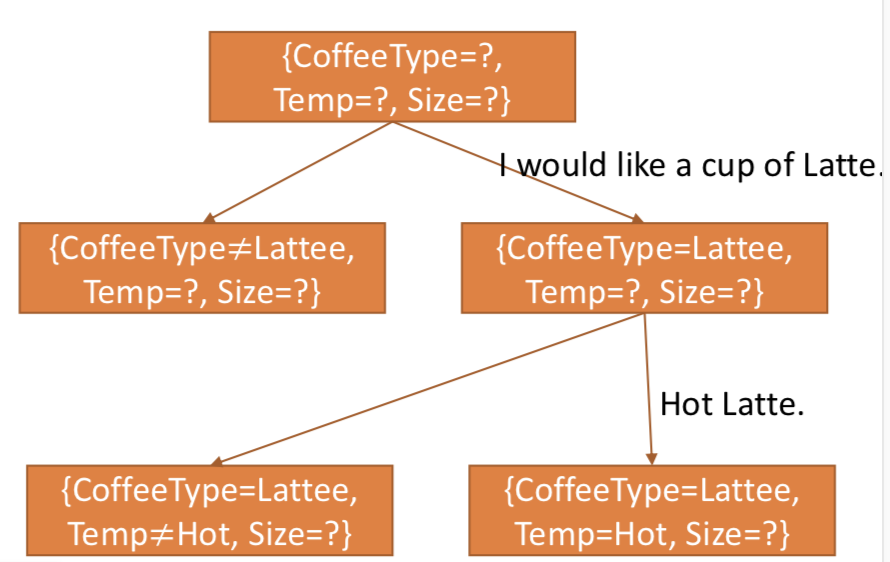
举例:第一轮判断类型是Latte的概率很高,所以可以忽略Frappuccino和Mocha的各自分别(这二者合并成一个partition)。最终需要维护的partition数量为2^2=4。
原文描述:
1 | HIS system uses a full state representation in which similar states are grouped into partitions and a single belief is maintained for each partition. The system typically maintains a dis- tribution of upto several hundred partitions corresponding to many thousands of dialogue states. |
- 优点:可以对任何两种状态之间的转换进行建模。
- 缺点:只有前n个状态被追踪。
资料:
对话状态的贝叶斯更新 Bayesian Update of Dialogue States (BUDS)
假设不同的槽位之间的取值是相互独立的。
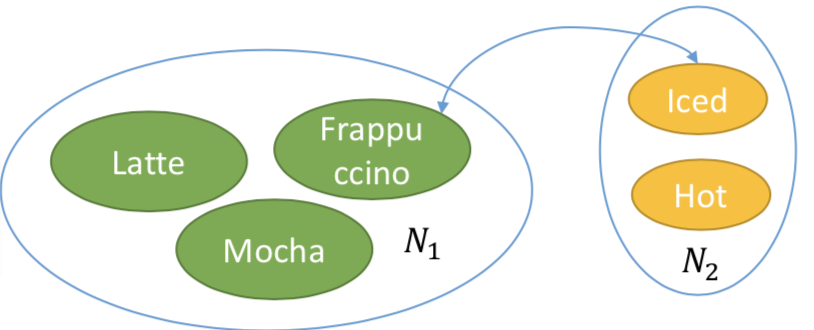
举例:需要维护的是N1+N2个状态数,这里即3+2=5种。
- 优点:可以追踪所有可能的状态。
- 缺点:不能处理复杂的转换。
资料:
状态追踪
Hand Crafted
输入上一个状态和当前的最佳(1-best)NLU结果,输出目前状态。
- 优点:不需要训练数据,适合冷启动。
- 缺点:需要人力手动设计规则,不能从实际对话中学习。不能充分挖掘NLU的n-best的结果。
Neural Belief Tracker
- 三个输入:上一次的系统动作+用户输入+候选的slot名-值对
- 输出:是否选用当前的候选slot对。
资料
- Global-Locally Self-Attentive Dialogue State Tracker (2018)
- Neural Belief Tracker: Data-Driven Dialogue State Tracking ,Mrkšić et al., ACL 2017
DPL
对话策略学习(Dialogue Policy Learning),通过当前的状态表示,做出响应动作的选择。常用监督学习+强化学习。
资料
- Continuously Learning Neural Dialogue Management (2016)
- A network-based end-to-end trainable task-oriented dialogue system. Wen et al. 2016b
*pdf - k-Nearest Neighbor Monte-Carlo Control Alg
*pdf - End-to-End Task-Completion Neural Dialogue Systems
*pdf*code - Transfer Learning for User Adaptation in Spoken Dialogue Systems
*pdf - Few-Shot Generalization Across Dialogue Tasks
*pdf*code - Sample-efficient Actor-Critic Reinforcement Learning with Supervised Data for Dialogue Management
*pdf - Deep Dyna-Q: Integrating Planning for Task-Completion Dialogue Policy Learning, ACL2018
*pdf*code - Switch-based Active Deep Dyna-Q: Efficient Adaptive Planning for Task-Completion Dialogue Policy Learning, aaai 2019
*pdf*code
DSTC
DSTC:Dialog System Technology Challenge。
https://www.microsoft.com/en-us/research/event/dialog-state-tracking-challenge/
DSTC1
- 内容:Bus route
- 主题:探索衡量指标。
- 示例:

资料
Knowledge Base
知识库引入:Memory network是引入知识库的典型的解决方案。
资料
A Knowledge-Grounded Neural Conversation Model (2017)
NLG
自然语言生成(Natural Language Generation)。
资料
- Semantically Conditioned LSTM-based Natural Language Generation for Spoken Dialogue Systems
*pdf
End2End
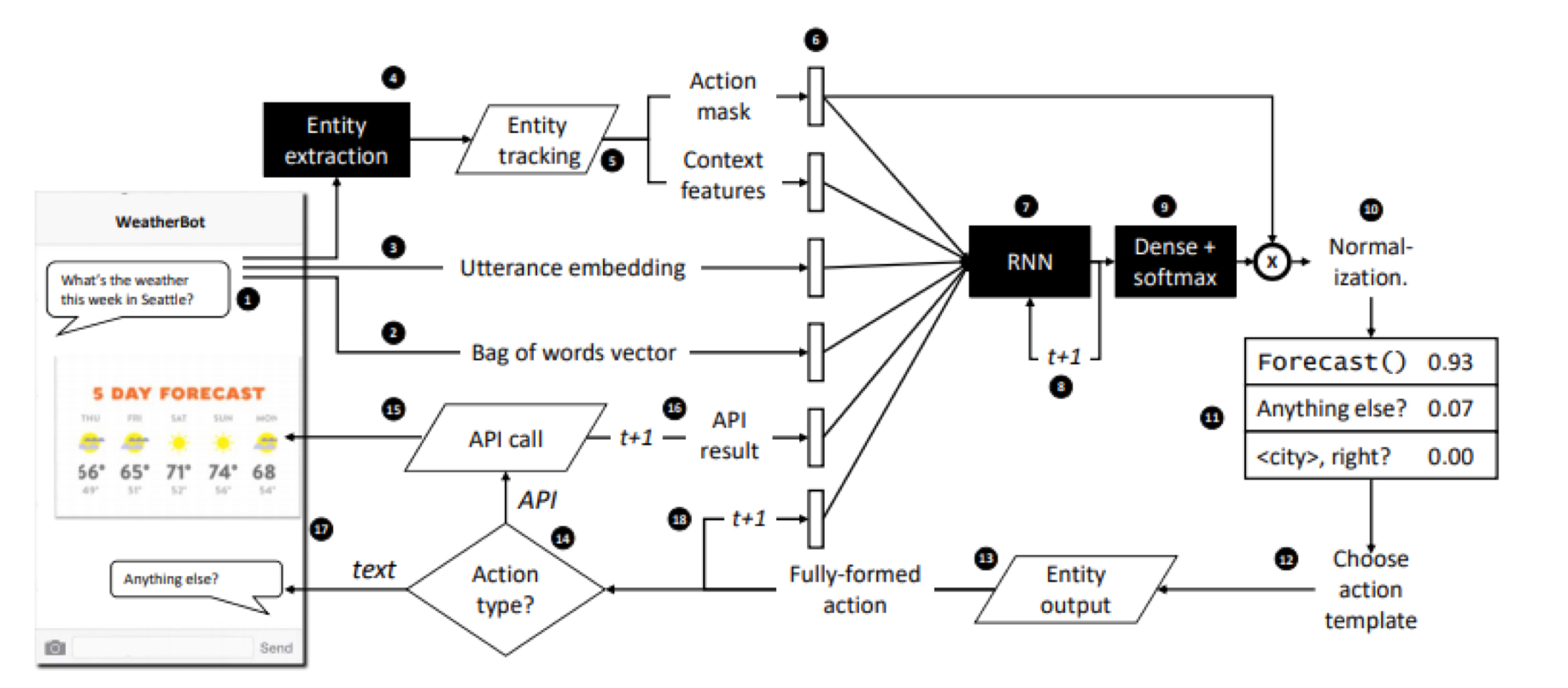
资料:
- Williams J D, Asadi K, Zweig Gc. Hybrid Code Networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning [J]. 2017:665-677.
- Towards end-to-end learning for dialog state tracking and management using deep reinforcement learning. (2016)
*pdf - End-to-End Task-Completion Neural Dialogue Systems
*pdf*code
开源项目
框架
- rasa: Open source chatbot framework with machine learning-based dialogue management - Build contextual AI assistants
- convlab : ConvLab is an open-source multi-domain end-to-end dialog system platform, aiming to enable researchers to quickly set up experiments with reusable components and compare a large set of different approaches, ranging from conventional pipeline systems to end-to-end neural models, in common environments.
数据
- Task-Oriented-Dialogue-Dataset-Survey : A dataset survey about task-oriented dialogue, including recent datasets and SoA results & papers.
Demo
- HotPepperGourmetDialogue :Restaurant Search System through Dialogue in Japanese.