Rasa学习总结
简述
Rasa是一个开源的基于机器学习的chatbot开发框架。其主要分成两大模块:Rasa NLU和Rasa Core。使用Rasa NLU + Rasa Core,开发者可以迅速构建自己的chatbot。本文先是分析了Rasa的结构组成,然后介绍开发者如何方便地利用Rasa构建自己的chatbot。
本文面向需要使用Rasa快速构建自己的chatbot的同学,还有想进一步了解Rasa框架结构的同学,以及想学习Rasa构建一个自己的chatbot框架的同学。
快速安装
1 | pip3 install rasa-x --extra-index-url https://pypi.rasa.com/simple |
Rasa NLU
Rasa NLU负责提供自然语言理解的工具,包括意图分类和实体抽取。
举例来说,对于输入:
1 | "I am looking for a Mexican restaurant in the center of town" |
Rasa NLU的输出是:
1 | { |
其中,Intent代表用户意图。Entities即实体,代表用户输入语句的细节信息。
预定义的pipeline
spacy_sklearn:- 1.使用
spaCy NLP进行tokenize和POS(Part of Speech,词性标注)。 - 2.使用
spaCy的featuriser来获取GloVe向量,然后pool成一个句子向量。 - 3.使用
sklearn分类器做意图分类。 - 4.使用
ner_crf模块来做命名实体识别。
- 1.使用
Rasa Core
Rasa整体框架图:
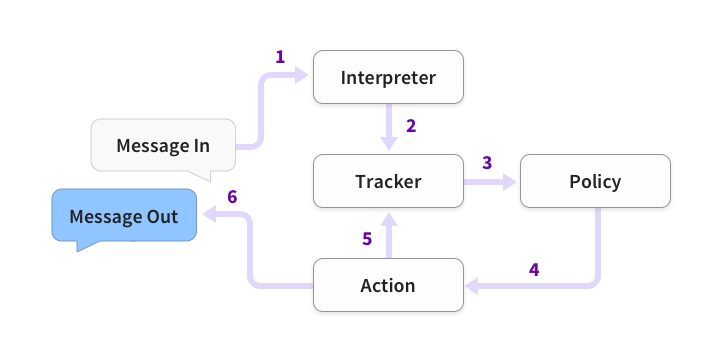
首先介绍一些核心概念。
Action
action是对系统响应的抽象。Rasa将对话管理视作一个分类问题,每轮都会在预先设定好的action集合中选出一个类别。Rasa Core定义了3中action:
default action:系统预先定义好的动作,如action_listen、action_restart、action_default_fallbackutter action:一般以utter_开头,这种action就只会单纯地给用户返回文本消息。这类的action无需具体实现代码,只需在配置文件中指定其对应的相应文本模板即可。custom action:用户可以任意编写此类action的代码。用户一般需要自己架设一个额外服务,然后在实现action时,让代码请求这个服务。
Tracker
Tracker是用于追踪对话状态的模块。当用户输入被解析后,会传入Tracker进行更新,然后系统会读取Tracker里的信息,作为策略判断的输入。
目前支持的tracker:
- InMemoryTrackerStore (default)
- RedisTrackerStore
- MongoTrackerStore
- Custom Tracker Store
Events
Events用于描述一个对话过程中任何可能发生的事情。
Dispatcher
Dispatcher的作用是将消息以各种形式发送给用户。
Action + Dispatcher + Tracker + Events:
当action被执行的时候,通常会将一个tracker对象传进去。这样它就可以利用各种相关的信息,比如slots、之前的utterance还有之前的action。
action被执行的时候,通常会调用dispatcher将消息返还给用户。执行过程本身并不直接修改tracker,但是执行的完成后可能会返回events,tracker可以消费这些event,并更新状态。
Policy
policy的输入是tracker记录的当前对话状态,输出是一个系统响应action。
policy包含一个featurizer。一个featurizer可以创造一个代表当前对话状态的向量。
特征包括以下三部分:
- 1.上轮动作
- 2.上轮的intent和entities
- 3.本轮的slots
一个很重要的超参max_history:指定了要考虑多少个之前的状态。通常取值为3-6。
Story
所谓的story有点像剧本,描述可能出现的对话场景。实际上story就是一个个用户输入intent(entities)和系统设定的输出action用于policy的训练。
格式:
1 | ## story名称 |

Interactive learning
交互式,让用户在每一次机器做出决定之后,给与反馈。
对于很难手动设计的边界情况非常有效。
原理:每次系统给出动作的时候,收集用户的y/n的信息,生成新的训练数据,对模型fine-tune。
动手实践
英文项目
官方起步项目:https://github.com/RasaHQ/starter-pack-rasa-stack
首先,按照网站上的README先安装好环境。
需要注意的文件:
data/nlu_data.md:训练nlu的数据。data/stories.md:训练policy的数据。nlu_config.yml:nlu模块相关的参数。domain.yml:包括intent、entities、slots、actions、templates的定义。actions.py:包括用户自定义的action代码。endpoints.yml:包括和自定义网络调用相关的参数。policies.yml:包括训练policy模型的参数。
中文项目
中文NLU:
Rasa NLU本身是只支持英文和德文的。中文因为其特殊性需要加入特定的tokenizer作为整个流水线的一部分。这个项目加入了jieba作为我们中文的tokenizer,这个适用于中文的rasa NLU的版本代码在github上:https://github.com/crownpku/rasa_nlu_chi