Few-Shot Generalization Across Dialogue Tasks(paper)
简介
Few-Shot Generalization Across Dialogue Tasks, 2018 * pdf * rasa repo * project data and code
这篇paper来自于基于深度学习的开源对话系统RASA。本文介绍了一种名为“Recurrent Embedding Dialogue Policy (REDP)”的模型,它将系统动作和对话状态映射到同一个向量空间。REDP包含一个记忆组件和基于神经图灵机的注意力机制。
动机
- 为什么是监督学习:强化学习的方案需要实现一个高精度的用户模拟器以及一个准确的奖励函数,对平台的应用开发者不友好。
- 更好的领域适应:focus在对话策略的领域适应(不考虑NLU的错误)。
模型介绍
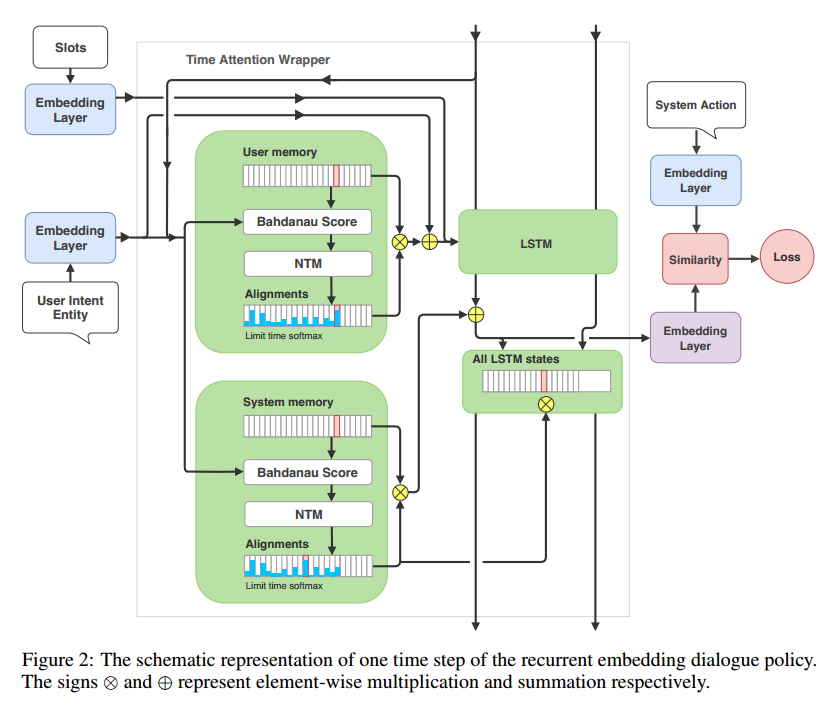
本模型输入是当前对话状态(Slots 和 Intent),输出是系统Action。看上图右侧,这是一个基于ranking的模型,即一开始介绍的,系统动作和对话状态映射到同一个向量空间,然后看哪个动作向量和当前的对话状态向量最接近。
这里的系统动作形如action_search_restaurant。模型在接收到一个系统动作时,先会将其拆分成{action, search, restaurant}。
图中的Embedding Layer这里使用参数独立的dense layer,生成用户意图、槽位、系统动作、LSTM输出的向量。
这里有两个memory和两个对应的attention,一个是system memory:保存之前的系统动作;一个是user memory:保存之前的用户响应。
数据
- 11条合作对话和几条不合作对话(很少):用于训练bootstrap policy。
- 根据这些策略,在每轮选择合作或者不合作(5种),生成了108个对话(30测试,78训练,hotel领域)。
- restaurant领域,50不合作、8合作对话。
实验结果
- REDP优于LSTM的basline
- REDP在hotel领域上,加了restaurant领域的数据优于不加restaurant领域的数据。
- 两个attention机制都有作用,其中syste attention的作用更大。