Attributes ---------- node_count : int The number of nodes (internal nodes + leaves) in the tree. capacity : int The current capacity (i.e., size) of the arrays, which is at least as great as `node_count`.
max_depth : int The maximal depth of the tree.
children_left : array of int, shape [node_count] children_left[i] holds the node id of the left child of node i. For leaves, children_left[i] == TREE_LEAF. Otherwise, children_left[i] > i. This child handles the case where X[:, feature[i]] <= threshold[i].
children_right : array of int, shape [node_count] children_right[i] holds the node id of the right child of node i. For leaves, children_right[i] == TREE_LEAF. Otherwise, children_right[i] > i. This child handles the case where X[:, feature[i]] > threshold[i].
feature : array of int, shape [node_count] feature[i] holds the feature to split on, for the internal node i.
threshold : array of double, shape [node_count] threshold[i] holds the threshold for the internal node i. value : array of double, shape [node_count, n_outputs, max_n_classes] Contains the constant prediction value of each node.
impurity : array of double, shape [node_count] impurity[i] holds the impurity (i.e., the value of the splitting criterion) at node i.
n_node_samples : array of int, shape [node_count] n_node_samples[i] holds the number of training samples reaching node i.
weighted_n_node_samples : array of int, shape [node_count] weighted_n_node_samples[i] holds the weighted number of training samples reaching node i.
# The decision estimator has an attribute called tree_ which stores the entire # tree structure and allows access to low level attributes. The binary tree # tree_ is represented as a number of parallel arrays. The i-th element of each # array holds information about the node `i`. Node 0 is the tree's root. NOTE: # Some of the arrays only apply to either leaves or split nodes, resp. In this # case the values of nodes of the other type are arbitrary! # # Among those arrays, we have: # - left_child, id of the left child of the node # - right_child, id of the right child of the node # - feature, feature used for splitting the node # - threshold, threshold value at the node #
# Using those arrays, we can parse the tree structure:
# 遍历树,获取每个结点的深度和每个结点是否是叶结点 # The tree structure can be traversed to compute various properties such # as the depth of each node and whether or not it is a leaf. node_depth = np.zeros(shape=n_nodes, dtype=np.int64) is_leaves = np.zeros(shape=n_nodes, dtype=bool) stack = [(0, -1)] # seed is the root node id and its parent depth whilelen(stack) > 0: node_id, parent_depth = stack.pop() node_depth[node_id] = parent_depth + 1
# If we have a test node if (children_left[node_id] != children_right[node_id]): stack.append((children_left[node_id], parent_depth + 1)) stack.append((children_right[node_id], parent_depth + 1)) else: is_leaves[node_id] = True
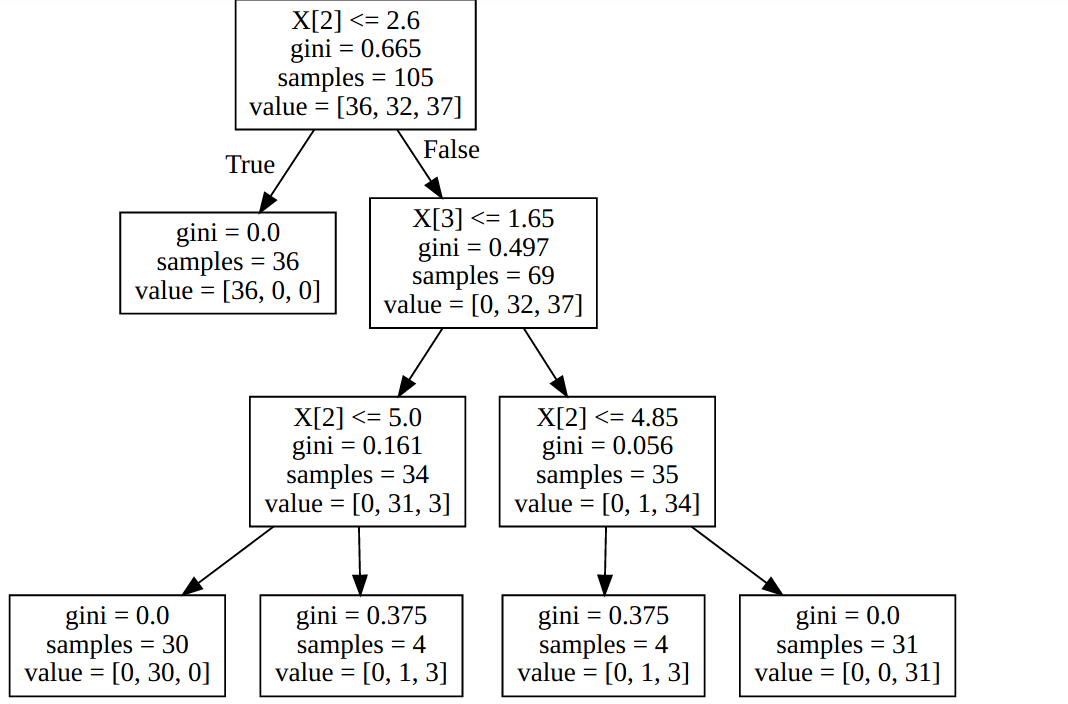
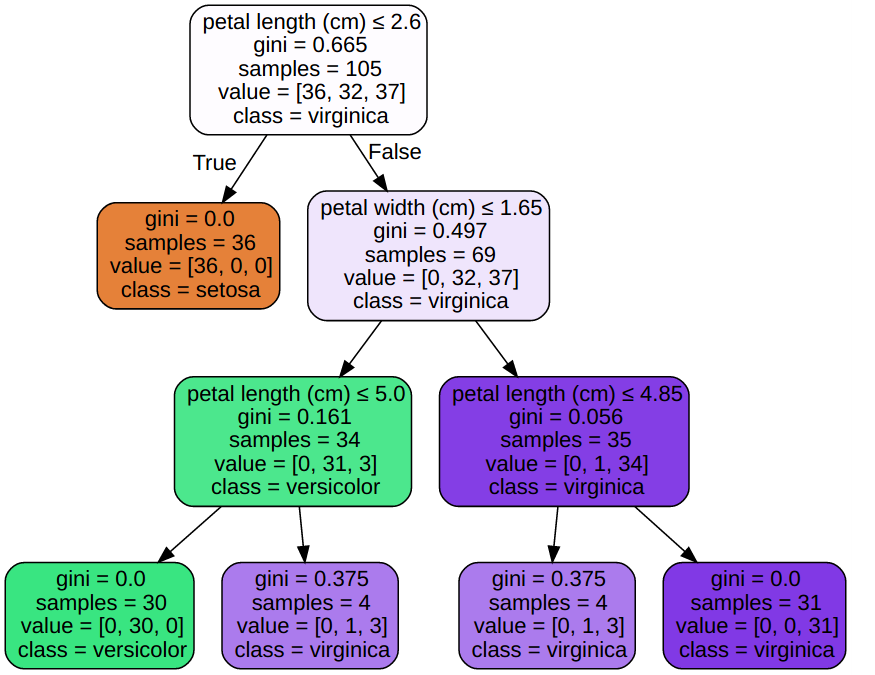
print("The binary tree structure has %s nodes and has " "the following tree structure:" % n_nodes) for i inrange(n_nodes): if is_leaves[i]: print("%snode=%s leaf node." % (node_depth[i] * "\t", i)) else: print("%snode=%s test node: go to node %s if X[:, %s] <= %s else to " "node %s." % (node_depth[i] * "\t", i, children_left[i], feature[i], threshold[i], children_right[i], ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14
The binary tree structure has 13 nodes and has the following tree structure: node=0 test node: go to node 1 if X[:, 0] <= 5.44999980927 else to node 6. node=1 test node: go to node 2 if X[:, 1] <= 2.80000019073 else to node 5. node=2 test node: go to node 3 if X[:, 0] <= 4.69999980927 else to node 4. node=3 leaf node. node=4 leaf node. node=5 leaf node. node=6 test node: go to node 7 if X[:, 0] <= 6.25 else to node 10. node=7 test node: go to node 8 if X[:, 1] <= 3.45000004768 else to node 9. node=8 leaf node. node=9 leaf node. node=10 test node: go to node 11 if X[:, 1] <= 2.54999995232 else to node 12. node=11 leaf node. node=12 leaf node.
# First let's retrieve the decision path of each sample. The decision_path # method allows to retrieve the node indicator functions. A non zero element of # indicator matrix at the position (i, j) indicates that the sample i goes # through the node j.
node_indicator = model.decision_path(x_test)
# Similarly, we can also have the leaves ids reached by each sample.
leave_id = model.apply(x_test)
# Now, it's possible to get the tests that were used to predict a sample or # a group of samples. First, let's make it for the sample.
# For a group of samples, we have the following common node. sample_ids = [0, 1] common_nodes = (node_indicator.toarray()[sample_ids].sum(axis=0) == len(sample_ids))
common_node_id = np.arange(n_nodes)[common_nodes]
print("\nThe following samples %s share the node %s in the tree" % (sample_ids, common_node_id)) print("It is %s %% of all nodes." % (100 * len(common_node_id) / n_nodes,))
1 2 3 4 5
Rules used to predict sample 0: decision id node 9 : (X_test[0, -2] (= 5.8) > -2.0)
The following samples [0, 1] share the node [0] in the tree It is 7 % of all nodes.