用python编写一个本地论文管理器
1. 介绍和引入
最近初学NLP相关的深度学习,下了很多论文,数量一多,发现论文管理是个问题。
首先论文数目一多,必须要按类别放到子文件夹下。但是某一篇论文,往往有多个主题。比如说某论文使用word2vec给短文本分类,那这篇论文既可以放在word2vec的目录下,也可以放在短文本的目录下,也可以放在分类的目录下。当你有天想去看了,往往又忘了是放在哪个子目录下了。再比如说,你下载了一些论文,下载的时候你知道这些论文的重要性(引用次数或者对项目的重要性)和紧急性(比如你三天之内都要看完)。但是当你把它放在某个子目录以后,当你有时间去看的时候,你忘了你当时最想看的那篇论文是什么了。
为此,我决定开发一个小工具来帮助我管理我的paper。我的思路是这样的:给每篇论文打上tag,标上重要程度和紧急程度。这样当我没有特定目的的时候,我就可以根据重要程度和紧急程度看小工具推荐的paper;当我想看某方面的paper时,我只需要查询下tag就可以找到相关主题的paper。
OK,有了思路,就可以着手实现了。
2.实现
实现这里不想讲太多,主要是设计程序的思路,源代码在文末给出,都有注释。
首先是图形化界面和命令行的选择,最终选择了命令行,开发速度更快,使用起来更直接。命令行的实现使用python自带的cmd模块实现。为了美化命令行的输出,参考使用了这里的终端输出彩色化和第三方的terminaltables。
数据存储选择sqlite,因为有数据的查询/插入/删除/更新操作,用数据库比文件要方便很多;而且sqlite是python自己支持的,不用再安装其他软件,属于轻量级的文件数据库,最适合这个任务。
3.安装
下载github上的源码以后,使用python2.7,只需要:
1 | pip install terminaltables |
然后就可以输入:
1 | python Manager.py |
启动程序。
4.使用
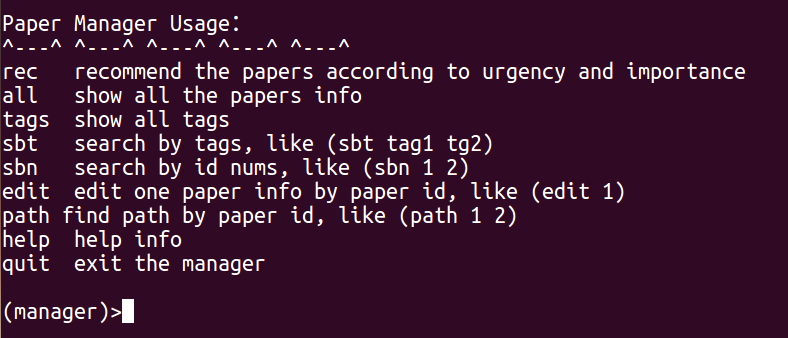
基本的命令:
1 | ^---^ ^---^ ^---^ ^---^ ^---^ |
5.演示:
a.录入目录
启动程序后,首先按照提示,输入你的paper的根目录。如果输错了,可以把user_set.pkl删掉,重新启动程序即可。我这里程序已经保存路径,所以跳过。
b.输入新paper的数据
每次启动程序后,程序都会去扫描paper的目录(以及子目录),有扫描到新paper就会提示录入新paper的数据。

按照提示录入即可,分别是重要性(importance),紧急性(urgency),都是1-5的整数,还有所有tag(用空格隔开),以及这篇论文是不是读过了。
所有扫描到的新论文录入信息以后,就会出现欢迎界面:
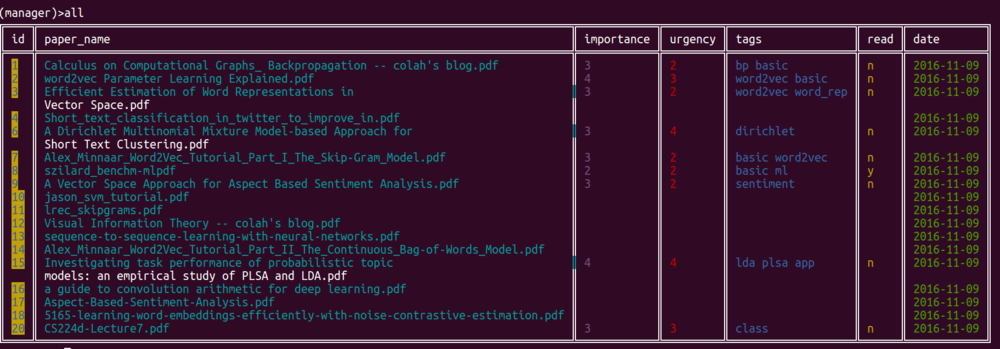
c.显示所有论文信息
输入:
1 | all |
d.显示录入的所有tag
1 | tags |

e.按照tag搜索paper
1 | sbt tag1 tag2 |
sbt(search by tag)
f.按照id号获取论文
1 | sbn num1 num2 |

g.按照id号获取论文路径
1 | path num1 num2 |

h.修改特定paper的info
1 | edit num |
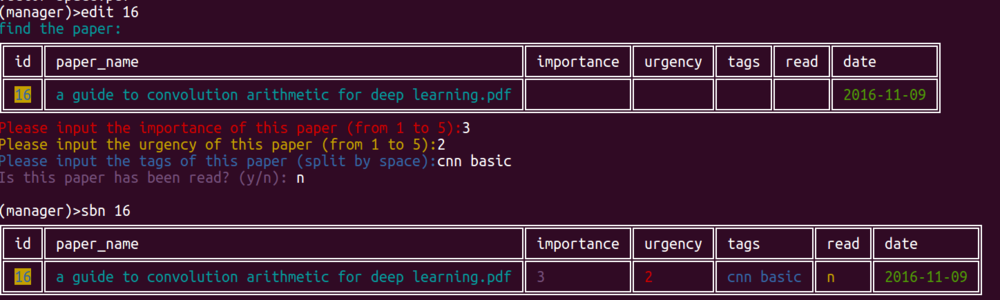
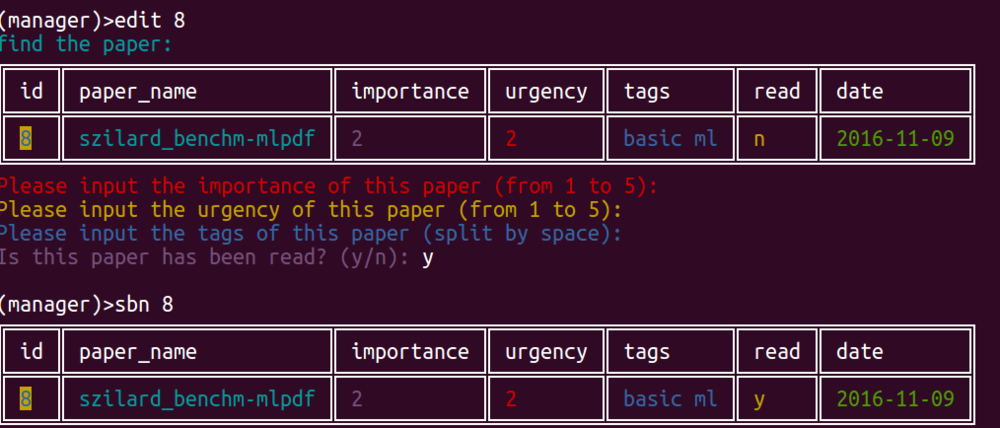
如果看完了某篇论文,想改read从n为y,也可以直接使用edit命令。不修改的字段直接回车,数据不会丢失。
如:
i.获取推荐
1 | rec |
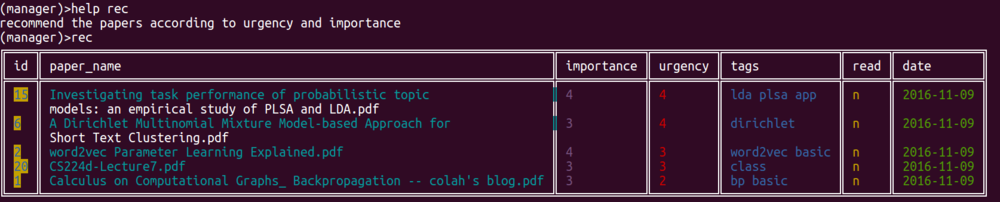
推荐规则是按照紧急程度降序,相同紧急程度按照重要程度降序,而且是read为n,就是没有标记读过的论文。
j.打开论文
1 | open num |
打开指定id的论文(使用系统默认的阅读器)。
k.获取帮助
1 | help |
l.退出
1 | quit |
6.最后
github源代码地址,喜欢留个star :>
这个工具只是用来方便自己的日常使用,一共只开发了两天的时间,有什么改进意见尽管提,但是不保证回去改哦~我要滚回去看paper了。