Python正则表达式梳理
最近在一个项目中大量使用正则表达式,对各种用法做个梳理。
简介
正则表达式的作用是检查一个字符串是否与某种模式匹配。Python中的re模块提供正则匹配相关的方法。
语法
Python正则表达式测试网站:https://pythex.org/
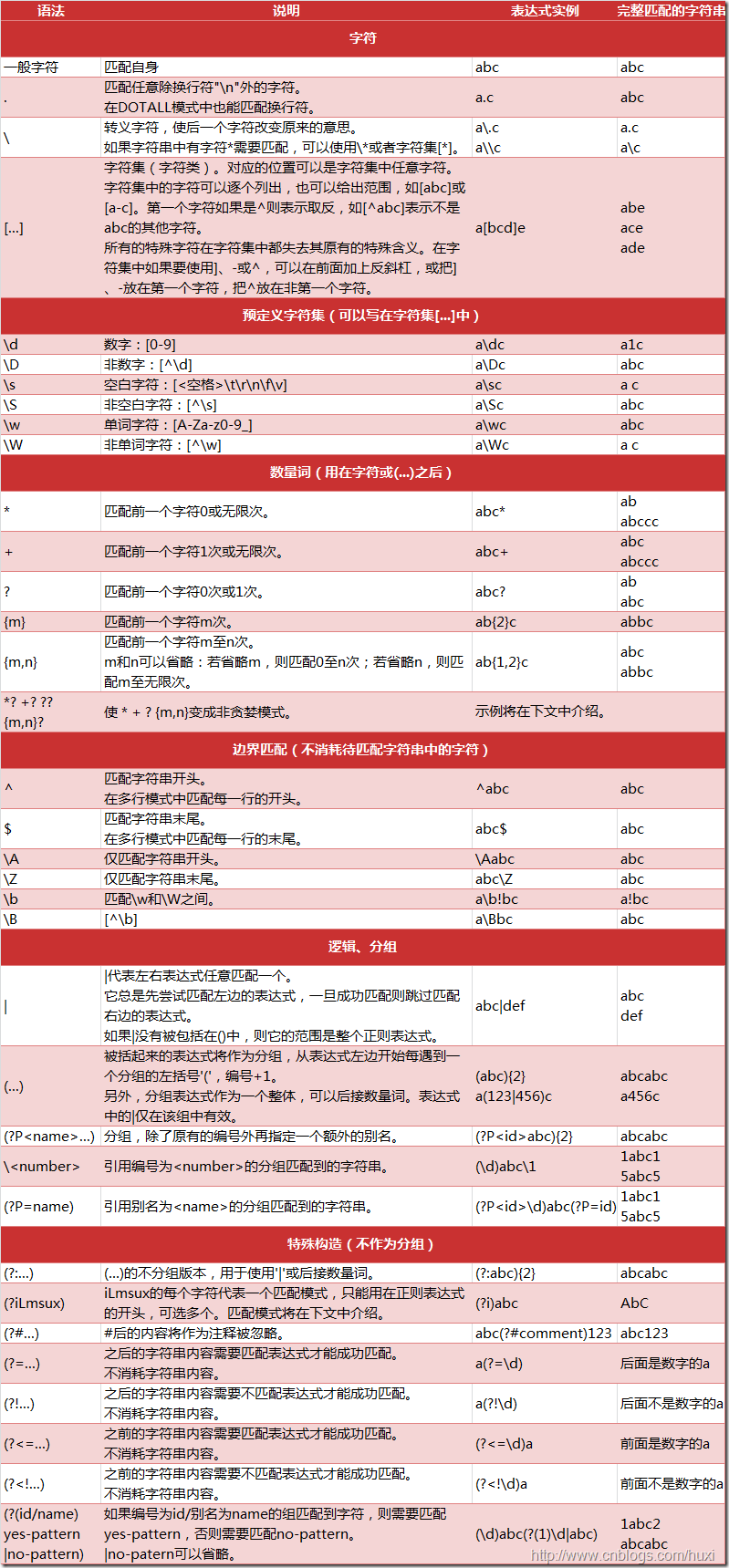
图片来自:https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
常用方法
re.match
re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,返回None。
函数语法:
1 | re.match(pattern, string, flags=0) |
1 | import re |
1 | 'www.didichuxing.com' |
re.search
re.search扫描整个字符串并返回第一个成功的匹配。
函数语法:
1 | re.search(pattern, string, flags=0) |
1 | # 匹配网址 |
1 | 'www.didichuxing.com' |
Match
re.match和re.search返回的都是一个Match 对象(如果成功匹配)。
Match对象又有如下常用的方法:
start([group]):返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。end([group]): 返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。span([group]):返回(start(group), end(group))。group([group1,…]):获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串,默认是0。groups([default]):以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。groupdict([default]): 返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。expand(template): 将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
注意:group(0)返回的是整个匹配的结果,group(n)或者group(name)是某个匹配的组。
1 | # 匹配数字 |
1 | match_3: <_sre.SRE_Match object; span=(4, 7), match='15元'> |
re.sub
实现字符串替换。
语法:
1 | re.sub(pattern, repl, string, |
注意,这里的repl可以是字符串也可以是一个函数。
1 | # 匹配数字 |
1 | '今天花了2元' |
1 | pattern_str = "(\d)+(元)" |
1 | '今天花了22元' |
re.compile
re.compile用于编译正则表达式,生成一个正则表达式Pattern对象。
语法:
1 | re.compile(pattern[, flags]) |
1 | pattern_str = "(\d)+(元)" |
Pattern
Pattern不能直接实例化,必须使用re.compile()进行构造。
常用方法:
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]): 这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]): 按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。findall(string[,pos[, endpos]]) | re.findall(pattern, string[, flags]): 搜索string,以列表形式返回全部能匹配的子串。finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]): 搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]): 使用repl替换string中每一个匹配的子串后返回替换后的字符串。subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]): 返回(sub(repl, string[, count]),替换次数)。
1 | test_str = "吃饭花费15元,坐车6元" |
1 | pattern.match: None |
3.7 flags
多个标志可以通过|来指定。
I(IGNORECASE): 忽略大小写。M(MULTILINE): 多行模式,改变^和$的行为。S(DOTALL): 点任意匹配模式,改变.的行为。L(LOCALE): 使预定字符类\w\W\b\B\s\S取决于当前区域设定。U(UNICODE): 使预定字符类\w\W\b\B\s\S\d\D取决于unicode定义的字符属性。X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。。
1 | pattern_str = "ABc" |
1 | I: <_sre.SRE_Match object; span=(0, 3), match='abc'> |
1 | pattern_str = "^ABc$" |
1 | None |
常用方式
直接找到匹配的子串
这是最常见的需求,提取出符合pattern的子串,一般用search可以搞定。
案例:
从文本里抽取手机号码:
1 | pattern_str = "\d{11}" # 11位的数字认为是手机号码 |
1 | 18801010101 |
找到匹配的子串中的一部分
比如匹配距离:从“125公里”中找到“125”,但是直接匹配数字可能是其他的数据,可能是“1天”、“3元钱”等。
这种情况使用分组即可。分组可以按照(?P<first>\d)起名,或者不起名,从1开始索引。
案例:
抽取距离数值:
1 | pattern_str = "(?P<distance>\d+)公里" |
1 | ['34'] |
还可以使用(?=)来实现:
1 | pattern_str = "\d+(?=公里)" |
1 | ['34'] |
(?=),(?!),(?<=),(?<!)都是属于不消耗字符串的操作,非常有用。!代表不等,<代表前面匹配。
复杂的替换
比如我们需要把所有的量词数字替换成一个特殊符号<number>。
一般使用sub可以解决。
参数repl接受函数时,参数是返回的Match对象。
1 | lambda match: repl_str + match.group(2) |
含义是将数量替换,单位保留。
案例:
替换数量:
1 | pattern_str = "(\d+)(个)" |
1 | 我需要买<number>个苹果和<number>个鸡蛋,预算是100元。 |
继续把上面这种情况复杂化,单位可能是个或者只:
1 | pattern_str = "(\d+)(?P<unit>个|只)" |
1 | 我需要买<number>个苹果和<number>只鸡蛋,预算是100元。 |
逻辑操作
接上面的案例,可能会遇到更复杂的或逻辑,甚至是否逻辑:
案例:
稍复杂的或:
1 | pattern_str = "\d+顿(?:麦当劳[A-Z]套餐|肯德基[0-9]号套餐)" |
1 | ['3顿麦当劳A套餐', '2顿肯德基3号套餐'] |
上面的(?:)不算入分组。
案例:
稍复杂的否,比如我想抽取所有的钱数,因此我认为带钱单位的数字和不带钱的单位的数字都是钱数,带其他单位的数字都忽略,为简化问题,不是钱的单位假设只有“号”和“天”,认为其他数字都是和钱数。
1 | pattern_str = "\d+(?!号|天)" |
1 | ['1000'] |