强化学习导论学习笔记——(一)
1. Introduction
书本介绍

作者: Richard S. Sutton / Andrew G. Barto
几乎是最权威的强化学习教材。
重要的符号表示
- $q_∗(a)$:动作a对应的真实价值(价值期望),true value (expected reward) of action a
- $Q_t(a)$:动作a在t时刻的估计价值,estimate at time t of $q_∗(a)$
- $N_t(a)$:在t时刻之前,动作a已经被选择的次数,number of times action a has been selected up prior to time t
- $H_t(a)$:在t时刻选择动作a的偏好程度,learned preference for selecting action a at time t
- $π_t(a)$:在t时刻选择动作a的概率,probability of selecting action a at time t
- $R_t$:给定策略$π_t$,在t时刻的期望奖励,estimate at time t of the expected reward given$π_t$
什么是强化学习
强化学习是“学习该如何去做”(learning what to do),即学习如何从某个状态映射到某个行为,来最大化某个数值的奖励信号。
强化学习的特征
强化学习两个最重要的特征:
- 试错(trial-and-error search ):agent需要不断尝试,通过reward的反馈学习策略。
- 延迟奖励(delayed reward) :某个时刻的action可能会对后面时刻的reward有影响(深远影响)。
Exploit vs Explore
- exploit: 代表利用已有的信息去获得最大的奖励。
- explore 代表去探索一些没有尝试过的行为,去获得可能的更大的奖励。
强化学习的几个要素
- policy: 状态到行为的映射,定义agent在某个状态下应该如何采取行为,state $\rightarrow$ action。
- reward function: 在某个状态下,agent能够收到的即时反馈。
- value function: 衡量在某个状态下,能够获得的长期反馈。
- modle (of the environment,可选的): 模型用来模拟环境的行为,给定一个状态和动作,模型可以预测下一个状态和奖励。
RL vs Evolutionary Methods
- Evolutionary Methods(遗传算法,具体可以回顾之前的博客),直接在policy空间中搜索,并计算最后的得分。通过一代代的进化来找寻最优policy。
- 遗传算法忽略了policy实际上是state到action的映射,它不关注agent和环境的互动,只看最终结果。
局限性
强化学习非常依赖状态(state)的概念。state既是策略函数和价值函数的输入,又是环境模型(model)的输入和输出。
Tic-Tac-Toe(井字棋)
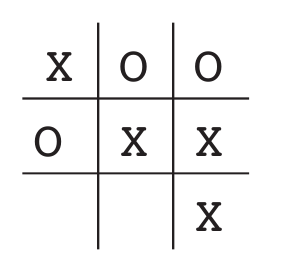
- 一个简单的应用强化学习的例子。
- 定义policy:任何一种局面下,该如何落子。
遗传算法解法:试很多种policy,找到最终胜利的几种,然后结合,更新。
强化学习解法:
- 1.建立一张表格,state_num × 1,代表每个state下,获胜的概率,这个表格就是所谓的value function,即状态到价值的映射。
- 2.跟对手下很多局。每次落子的时候,依据是在某个state下,选择所有可能的后继state中,获胜概率最大的(value最大的)。这种方法即贪婪法(Exploit)。偶尔我们也随机选择一些其他的state(Explore)。
- 3.back up后继state的v到当前state上。$V(s)\leftarrow V(s)+\alpha[V(s’)-V(s)]$,这就是所谓的差分学习(temporal-difference learning),这么叫是因为$V(s’)-V(s)$是两个时间点上的两次估计的差。
代码分析
游戏实现:
用1代表白棋,-1代表黑棋,若有连续的三个数之和为3则白赢,-3则黑赢。若所有绝对值之和为9,则游戏为平局。
1 | for result in results: |
定义状态字典:
1 | all_states = dict() |
其中,键名是状态的哈希值,值是状态对象以及该状态是否是终止状态。哈希值计算:
1 | # compute the hash value for one state, it's unique |
可以看到,状态的个数理论上应该是$3^9=19683$个,下面的价值表格的键数也一样是这个数字。
价值表格也是用dict实现:
1 | self.estimations = dict() |
backup:
1 | # update value estimation |
决策使用epsilon-greedy:
1 | # choose an action based on the state |
可以在终端和训练好的ai player对弈:
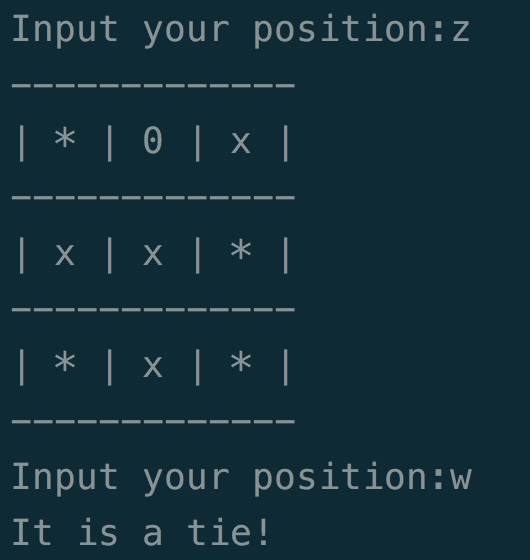
我试了好几局,都是平局,看来训练的还是不错的。
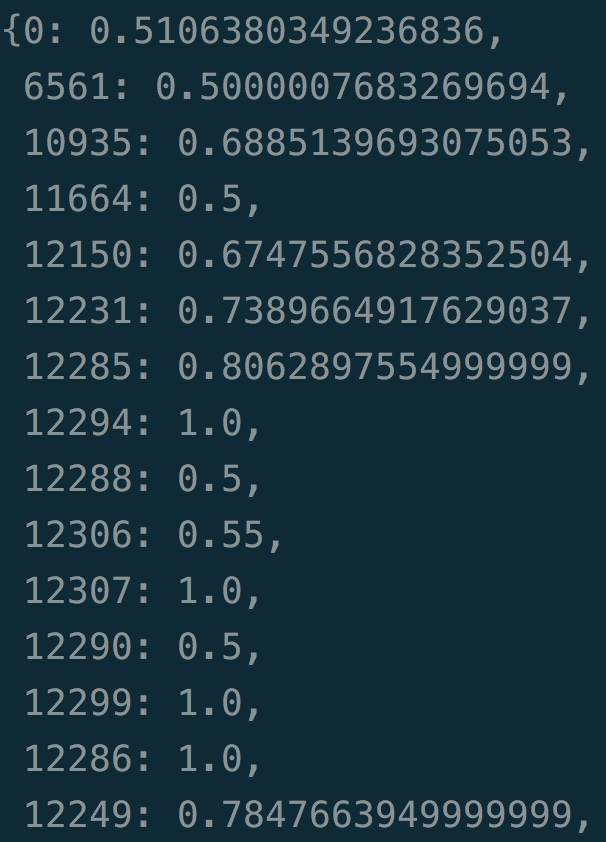
模型训练好后,保存的数据就是价值表格。但我们从中也可以看到一个问题,一个像tic-tac-toe这么简单的问题,使用价值表格保存所有状态的价值,也需要耗费大量的存储。