强化学习导论学习笔记——(四)
4. Dynamic Programming
DP方法简介
- 由于其大量的计算损耗,已经不实用,但理论上非常重要。
- 本书后续的所有方法可以看做想要取得和DP类似的效果;只不过是减少了计算或者假设没有完美的环境模型。
- 假设解决的问题是有限的MDP,即给定动作a,状态s,和奖励r,可以通过$p(s’,r|s,a)$描述动态变化。
Policy Evaluation
评估一个策略的好坏。
策略评估:计算某个policy对应的价值函数,也被称为prediction problem。
更新方法:使用上一章讲的Bellman Expectation Euqation for $v_{\pi}$:
$$v_{\pi}(s) = \sum_a\pi(a|s)\sum_{s’,r}p(s’,r|s,a)[r+\gamma v_{\pi}(s’)];;\forall s \in S$$

核心代码:
1 | src = new_state_values if in_place else state_values |
其中,step函数即MDP的模型,会根据当前状态和动作产生下一个状态和奖励。
Policy Improvement
在当前的策略和相应的价值函数的基础上,使用价值函数贪婪地更新当前策略的过程。
policy improvement theorem:对所有的$s \in S$,有$q_{\pi}(s, \pi’(s)) \geq v_{\pi}(s)$,则$v_{\pi’}\geq v_{\pi}(s)$,即策略$\pi’$优于策略$\pi$。
greedy policy:
$$\pi’(s)=\underset{a}{argmax}q_{\pi}(s,a)=\underset{a}{argmax}\sum_{s’, r}p(s’, r|s,a)[r+\gamma v_{\pi}(s’)]$$
核心代码:
1 | policy = np.zeros(value.shape, dtype=np.int) |
Policy Iteration
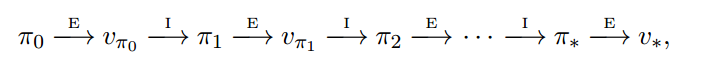
其中,$E$代表策略的evaluation,$I$代表策略的improvement。简单地说,Policy Iteration就是不断地评估策略然后改进策略。

核心代码:
1 | policy_change = (new_policy != policy).sum() |
Value Iteration
Policy Iteration的缺点:每一次迭代都要评估策略,而每一次策略评估本身都是一个迭代过程。
$v_{k+1}(s)=\underset{a}{max} E[R_{t+1}+\gamma v_k(S_{t+1})|S_t=s, A_t=a]$
$=\underset{a}{max}\sum_{s’,r}p(s’,r|s,a)[r+\gamma v_k(s’)]$
实际上就是Bellman Optimality Euqation for $v_*(s)$。

Value Iteration简单地说就是每次评估价值的时候直接用可能的用最优价值函数更新价值函数(这样的每一步不涉及策略本身);在确定已经获得比较准确的价值评估之后,再一次性确定策略。
核心代码:
1 | # value iteration |