第十六章:Structured Probabilistic Models for Deep Learning
16. Structured Probabilistic Models for Deep Learning
多样化的任务:
除了分类任务以外,很多任务需要对输入数据整个结构有完整理解,包括:
- 1.概率密度估计(Density Estimation):给定一个输入x,机器学习系统返回一个对数据生成分布的真实密度函数p(x)的估计。
- 2.去噪(Denoising):给定一个受损的或者观察有误的输入数据$\tilde{x}$,机器学习系统返回一个对原始的真实x的估计。
- 3.缺失值的填补(Missing Value Imputation):给定x的某些元素作为观察值,模型被要求返回一些或者全部未观察值的估计或者概率分布。
- 4.采样(Sampling):模型从分布$p(x)$中抽取新的样本。
非结构化建模的挑战
如果我们希望对一个包含$n$个离散变量并且每个变量都能取$k$个值的$x$的分布建模,那么最简单的表示$P(x)$的方法需要存储一个可以查询的表格。
这个表格记录了每一种可能值的概率,则需要$k^n$个参数。
非结构化建模不可行的原因:
- 1.内存:前面提到的存储参数的开销。
- 2.统计的有效性:当模型中的参数个数增加时,使用统计估计器估计这些参数所需要的训练数据数量也需要相应地增加。
因为基于查表的模型拥有天文数字级别的参数,为了准确地拟合,相应的训练集的大小也是相同级别的。 - 3.运行时间:推断的开销。比如推断边缘分布$P(x_1)$或者条件分布$P(x_2∣x_1)$。
计算这样的分布需要对整个表格的某些项进行求和操作,开销也很大。 - 4.运行时间:采样的开销。最简单的方法就是从均匀分布中采样,$u∼U(0,1)$,然后把表格中的元素累加起来,直到和大于u,然后返回最后一个加上的元素。最差情况下,这个操作需要读取整个表格。
本质问题:基于表格操作的方法的主要问题是我们显式地对每一种可能的变量子集所产生的每一种可能类型的相互作用建模。
在实际问题中我们遇到的概率分布远比这个简单。 通常,许多变量只是间接地相互作用。
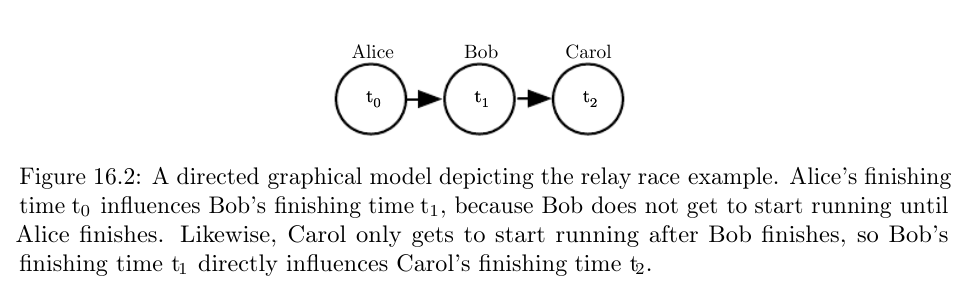
接力跑问题
对接力跑步比赛中一个队伍完成比赛的时间进行建模。
假设这个队伍有三名成员:Alice, Bob和Carol,分别对应1/2/3棒。
如果我们已经知道了Bob的完成时间,知道Alice的完成时间对估计Carol的完成时间并无任何帮助。
这意味着我们可以通过两个相互作用来建模这个接力赛。
即,我们可以忽略第三种间接的相互作用,即Alice的完成时间对Carol的完成时间的影响。
用接力跑问题分析非结构化建模的问题:如果我们把10分钟分为100份,那么三个离散随机变量$t_1$,$t_2$,$t_3$都有100种可能值。于是,非结构化建模要表示$p(t_0,t_1,t_2)$需要保存999999种可能值。
图模型
图模型的每个结点表示一个随机变量,每条边表示一个直接相互作用(direct interaction)。
有向图模型(Directed Graphical Model)
有向图模型是一种结构化概率模型,也被称为信念网络(Belief Network)或者贝叶斯网络(Baysian Network)。箭头所指的方向表示了这个随机变量的概率分布是由其他变量的概率分布所定义的。
画一个从结点$a$到结点$b$的箭头表示了我们用一个条件分布来定义b,而a是作为这个条件分布符号右边的一个变量。
正式地说,变量$x$的有向概率模型是通过有向无环图$G$和一系列局部条件概率分布$p(x_i∣Pa_G(x_i))$来定义的,其中$Pa_G(x_i)$表示结点$x_i$的所有父结点。
$x$的概率分布可以表示为$p(x)=\underset{i}{∏}p(x_i∣Pa_G(x_i))$。通常意义上说,对每个变量都能取$k$个值的$n$个变量建模,基于建表的方法需要的复杂度是$O(k^n)$。
但如果用一个有向图模型来对这些变量建模:**$m$代表图模型的单个条件概率分布中最大的变量数目(包括在条件符号的左和右)**,那么对这个有向模型建表的复杂度大致$O(k^m)$。
只要我们在设计模型时使其满足$m≪n$,那么复杂度就会被大大地减小。
有向图模型描述接力跑问题:$p(t_0,t_1,t_2)=p(t_0)p(t_1∣t_0)p(t_2∣t_1)$。那么,记录$t_0$的分布需要存储99个值,给定$t_0$情况下$t_1$的分布需要存储9900个值,给定$t_1$情况下$t_2$的分布也需要存储9900个值。
加起来总共需要存储19,899个值。 这意味着使用有向图模型将参数的个数减少了超过50倍!
https://raw.githubusercontent.com/applenob/reading_note/master/res/race.png
{kind=link}
感冒生病问题
你是否生病,你的同事是否生病以及你的室友是否生病。
无向图模型(Undirected Graphical Model)
无向模型,也被称为马尔可夫随机场(Markov random fields, MRFs)或者是马尔可夫网络(Markov networks)。
当相互的作用并没有本质性的指向,或者是明确的双向相互作用时,使用无向模型更加合适。
正式地说,一个无向模型是一个定义在无向模型G上的结构化概率模型。
对于图中的每一个团C,**一个因子(factor)$ϕ(C)$(也称为团势能)**,衡量了团中变量每一种可能的联合状态所对应的密切程度。这些因子都被限制为是非负的。
它们一起定义了未归一化概率函数:$\tilde{p}(x)=_{C∈G}ϕ(C)$。
只要所有团中的结点数都不大,那么我们就能够高效地处理这些未归一化概率函数
无向图描述感冒生病问题:假设你的室友和同事并不认识,所以他们不太可能直接相互传染一些疾病,比如说感冒。 这个事件太过罕见,所以我们不对此事件建模。
然而,很有可能其中之一将感冒传染给你,然后通过你再传染给了另一个人。你健康状况的随机变量记作$h_y$,对应你的室友健康状况的随机变量记作$h_r$,你的同事健康的变量记作$h_c$。
https://raw.githubusercontent.com/applenob/reading_note/master/res/cold.png
{kind=link}
因子(团势能):
https://raw.githubusercontent.com/applenob/reading_note/master/res/factor.png
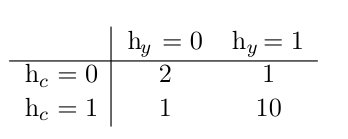{kind=link}
配分函数(Partition Function):因为$\tilde{p}(x)$是为归一化的概率,于是$p(x)=\frac{1}{Z}\tilde{p}(x)$。
归一化常数Z被称作是配分函数,是关于参数Θ的函数,这是一个从统计物理学中借鉴的术语。
由于Z通常是由对所有可能的x状态的联合分布空间求和或者求积分得到的,它通常是很难计算的。 在深度学习中,$Z$通常是难以处理的。
由于$Z$难以精确地计算出,我们只能使用一些近似的方法。
基于能量的模型(Energy-Based-Models):无向模型中许多有趣的理论结果都依赖于$∀x, \tilde{p}(x)>0$,这个假设。
使这个条件满足的一种简单方式是使用基于能量的模型,其中$\tilde{p}(x)=exp(−E(x))$,$E(x)$被称作是能量函数。
对所有的$z$,$exp(z)$都是正的,这保证了没有一个能量函数会使得某一个状态$x$的概率为0。
服从上面形式的任意分布都是玻尔兹曼分布的一个实例,基于这个原因,我们把许多基于能量的模型称为玻尔兹曼机。
分离(seperation)和d-分离(d-seperation)
图模型中的边告诉我们哪些变量直接相互作用。 同时,我们经常需要知道哪些变量间接相互作用。
也就是说,我们想知道在给定其他变量子集的值时,哪些变量子集彼此条件独立。
分离(seperation):如果图结构显示给定变量集S的情况下变量集A与变量集B无关,那么我们声称给定变量集S时,变量集A与另一组变量集B是分离的。
连接两个变量a和b的连接路径只包含由未观察变量,那么这些变量不是分离的。 如果它们之间没有路径,或者所有路径都包含可观测的变量,那么它们是分离的。
只包含由未观察变量的路径是活跃(active)的,而包括可观察变量的路径称为”非活跃”(inactive)的。
d-分离(d-seperation):“d”代表”依赖”的意思;有向图中d-分离的定义与无向模型中分离的定义相同:如果图结构显示给定变量集S时,变量集A与变量集B无关,那么我们认为给定变量集S时,变量集Ad-分离于变量集B。
如果两个变量之间存在活跃路径,则两个变量是依赖的,如果没有活跃路径,则为d-分离。 在有向网络中,确定路径是否活跃有点复杂。
判断有向图路径是否活跃的细节:两个变量之间存在活跃路径的四中情况:https://raw.githubusercontent.com/applenob/reading_note/master/res/d-sep.png
{kind=link}
下图中:a和b是d-seperated;给定c时,a和e是d-seperated;给定c时,d和e是d-seperated。给定c,a和b不是d-seperated;给定d,a和b不是d-seperated。
https://raw.githubusercontent.com/applenob/reading_note/master/res/d-sep-2.png
{kind=link}
有向模型到无向模型
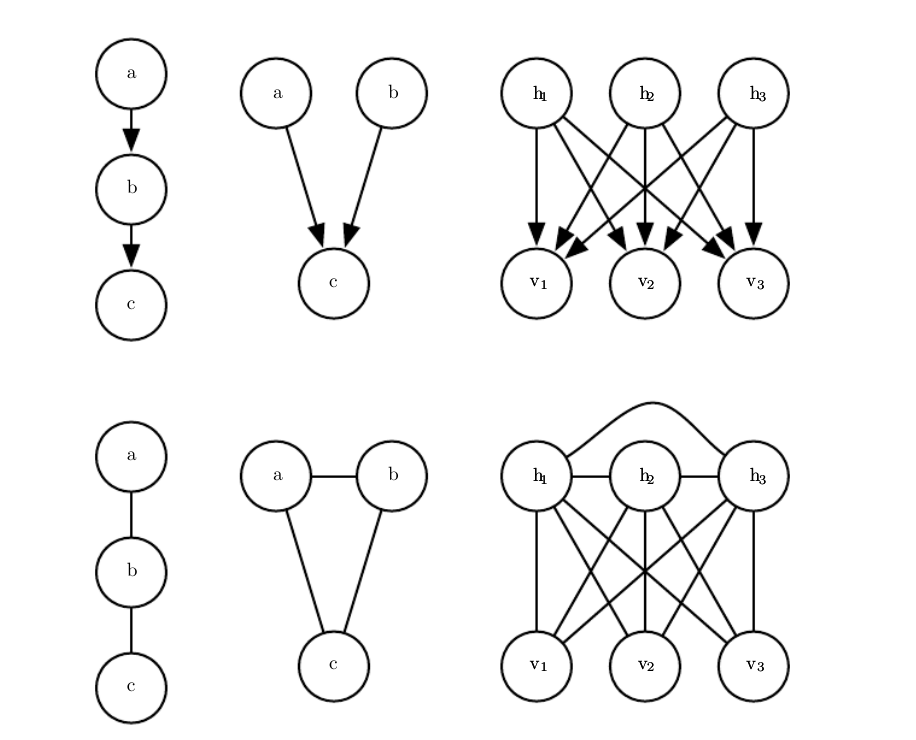
有向模型能够使用一种无向模型无法完美表示的特定类型的子结构,这个子结构被称为不道德(immorality)。
这种结构出现在当两个随机变量a和b都是第三个随机变量c的父结点,并且不存在任一方向上直接连接a和b的边时。
https://raw.githubusercontent.com/applenob/reading_note/master/res/d2ud.png
{kind=link}
无向模型到有向模型
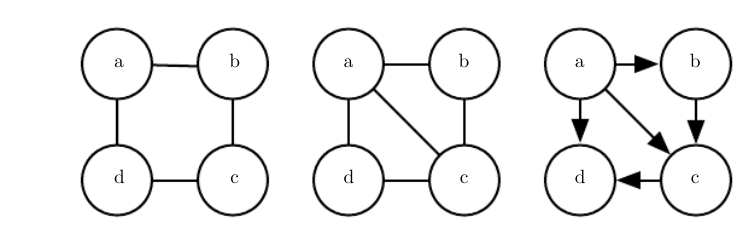
无向模型也可能包括有向模型不能完美表示的子结构:如果U包含长度大于3的环(loop),则有向图D不能捕获无向模型U所包含的所有条件独立性,除非该环还包含弦(chord)。
环指的是由无向边连接的变量序列,并且满足序列中的最后一个变量连接回序列中的第一个变量。
弦是定义环序列中任意两个非连续变量之间的连接。
如果U具有长度为4或更大的环,并且这些环没有弦,我们必须在将它们转换为有向模型之前添加弦。
https://raw.githubusercontent.com/applenob/reading_note/master/res/ud2d.png
{kind=link}
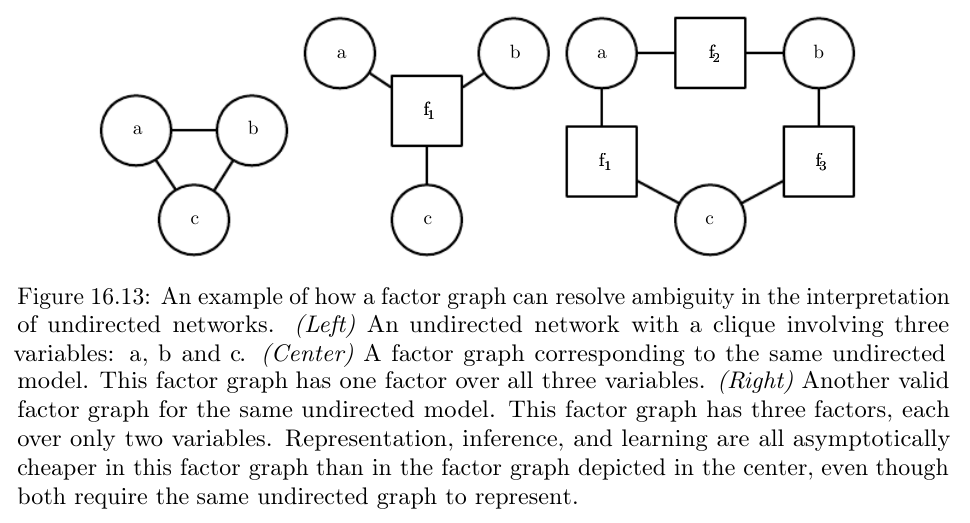
因子图(Factor Graphs)
因子图是从无向模型中抽样的另一种方法,它可以解决标准无向模型语法中图表达的模糊性。 些节点被绘制为圆形。
就像在标准无向模型中一样,这些节点对应于随机变量。 其余节点绘制为方块。 这些节点对应于未归一化概率函数的因子ϕ。
https://raw.githubusercontent.com/applenob/reading_note/master/res/factor-model.png
{kind=link}
图模型的采样(Sampling)
有向图模型的采样比较简单,称为原始采样(ancestral sampling)。
始采样的基本思想是将图中的变量$x_i$使用拓扑排序,使得对于所有$i$和$j$,如果$x_i$是$x_j$的一个父亲结点,则$j$大于$i$。
然后可以按此顺序对变量进行采样。
换句话说,我们可以首先采$x_1\sim P(x_1)$,然后采$x_2\sim P(x_2∣Pa_G(x_2))$,以此类推,直到最后我们从$P(x_n∣Pa_G(x_n))$中采样。
从无向模型中抽取样本是一个成本很高的多次迭代的过程。 理论上最简单的方法是Gibbs采样。
结构化概率模型的深度学习方法
在图模型中,我们可以根据图模型的图而不是计算图来定义模型的深度。
如果从潜变量$h_i$到可观察变量的最短路径是$j$步,我们可以认为潜变量$h_j$处于深度j。
我们通常将模型的深度描述为任何这样的$h_j$的最大深度。
深度学习模型通常具有比可观察变量更多的潜变量。
潜变量的设计方式在深度学习中也有所不同。
另一个明显的区别是深度学习方法中经常使用的连接类型。
深度图模型通常具有大的与其他单元组全连接的单元组,使得两个组之间的相互作用可以由单个矩阵描述。
在深度学习中使用的模型倾向于将每个可见单元$v_i$连接到非常多的隐藏单元$h_j$上,从而使得h可以获得一个$v_i$的分布式表示。
最后,图模型的深度学习方法的一个主要特征在于对未知量的较高容忍度。
图模型举例:受限玻尔兹曼机(Restricted Boltzmann Machine)简介
具体关于rbm的内容在第20章笔记。
标准的RBM是具有二值的可见和隐藏单元的基于能量的模型,其能量函数为:$E(v,h)=−b^⊤v−c^⊤h−v^⊤Wh$,其中$b$,$c$和$W$都是无约束、实值的可学习参数。
模型的一个重要方面是在任何两个可见单元之间或任何两个隐藏单元之间没有直接的相互作用(从图上理解即横向没有连线,因此称为”受限”)。
因此,有良好的性质$p(h∣v)=∏_ip(h_i∣v)$,以及$p(v∣h)=∏_ip(v_i∣h)$。
对于二元的受限玻尔兹曼机,我们可以得到:
$p(h_i=1∣v)=σ(v^⊤W:,i+b_i),p(h_i=0∣v)=1−σ(v^⊤W_{:,i}+b_i)$
https://github.com/applenob/reading_note/raw/master/res/rbm.png
{kind=link}