CNN Sentence Classification (with Theano code)
1. Intro
1 | 本篇博客来细说CNN在NLP中的一大应用————句子分类。通过Yoon Kim的论文介绍一个应用,分析代码,并重构代码。 |
传统的句子分类器一般使用SVM和Naive Bayes。传统方法使用的文本表示方法大多是“词袋模型”。即只考虑文本中词的出现的频率,不考虑词的序列信息。传统方法也可以强行使用N-gram的方法,但是这样会带来稀疏问题,意义不大。
CNN(卷积神经网络),虽然出身于图像处理,但是它的思路,给我们提供了在NLP应用上的参考。“卷积”这个术语本身来自于信号处理,它的物理意义可以参考知乎上关于“复利”的回答,或者参考colah大神的博客。简单地说就是一系列的输入信号进来之后,系统也会有一系列的输出。但是并不是某一时刻的输出只对应该时刻的输入,而是根据系统自身的特征,每一个时刻的输出,都和之前的输入相关。那么如果文本是一些列输入,我们当然希望考虑词和词的序列特征,比如“Tom的 手机 ”,使用卷积,系统就会知道“手机是tom”的,而不是仅仅是一个“手机”。
或者更直观地理解,在CNN模型中,卷积就是拿kernel在图像上到处移动,每移动一次提取一次特征,组成feature map,
这个提取特征的过程,就是卷积。
接下来,我们看看Yoon Kim的paper:Convolutional Neural Networks for Sentence Classification (EMNLP 2014)
2. 论文框架介绍
Yoon Kim 自己画的结构图:

具体结构介绍:
1.输入层
可以把输入层理解成把一句话转化成了一个二维的图像:每一排是一个词的word2vec向量,纵向是这句话的每个词按序排列。输入数据的size,也就是图像的size,n×k,n代表训练数据中最长的句子的词个数,这里是64(不够64个词的句子采用zero padding),k是embbeding的维度,这里是300。所谓的static和non-static的chanel解释如下:
- CNN-rand: 所有的word vector都是随机初始化的,同时当做训练过程中优化的参数;
- CNN-static: 所有的word vector直接使用无监督学习即Google的Word2Vector工具(COW模型)得到的结果,并且是固定不变的;
- CNN-non-static: 所有的word vector直接使用无监督学习即Google的Word2Vector工具(COW模型)得到的结果,但是会在训练过程中被Fine tuned;
- CNN-multichannel: CNN-static和CNN-non-static的混合版本,即两种类型的输入; 从输入层还可以看出kernel的size。很明显kernel的高(h)会有不同的值,图上有的是2,有的是3。这很容易理解,不同的kernel想获取不同范围内词的关系;和图像不同的是,nlp中的cnn的kernel的宽(w)一般都是图像的宽,也就是word2vec的维度,这也可以理解,因为我们需要获得的是纵向的差异信息,也就是不同范围的词出现会带来什么信息。
2.卷积层
由于kernel的特殊形状,因此卷积后的feature map是一个宽度是1的长条。
3.池化层
这里使用是MaxPooling,并且一个feature map只选一个最大值留下。这被认为是按照这个kernel卷积后的最重要的特征。
4.全连接层
这里的全连接层是带dropout的全连接层和softmax。
3. 论文实验介绍
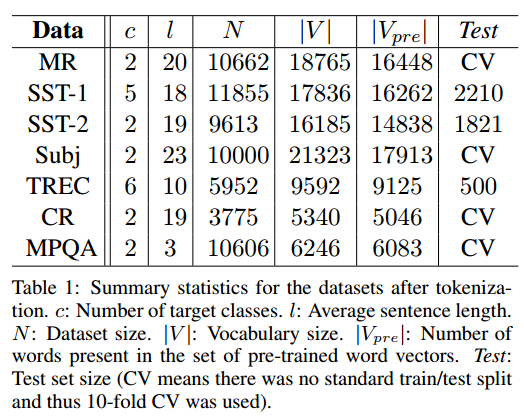
数据
1.word2vec使用谷歌预训练的GoogleNews-vectors-negative300.bin
2.数据集
训练和调参
- filter window(kernel)的高度(h):3,4,5;每个高度的Feature Map的数量为100,一共300个Feature Map;
- Dropout rate 0.5;
- L2 constraint (正则化限制权值大小)不超过3;
- mini-batch size 50;
- 通过网格搜索方法(Grid Search)得到的最优参数;
- 优化器使用Adadelta。
结果

4.试着跑跑
Yoon Kim在GitHub上分享了自己的代码和数据集MR(Movie Review, 只有两个类,neg和pos)。
让我们动手跑跑这个程序!
1.加载数据集
1 | python process_data.py /home/cer/Data/GoogleNews-vectors-negative300.bin |
1 | loading data... data loaded! |
2.跑模型
使用预先加载的word2vec,并且不改变。
注:为了便于显示cv个数从10减到2。
1 | THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python conv_net_sentence.py -nonstatic -word2vec |
1 | Using gpu device 0: GeForce GTX 960M (CNMeM is disabled, cuDNN not available) |
5. 代码梳理
接下来研究研究Yoon Kim的代码,看看像这样的一个Deep NLP的应用,是怎么实现的。
5.1 大体结构:
process_data.py:
数据预处理,数据以[revs, W, W2, word_idx_map, vocab]保存在pkl文件“mr.p”中。
revs的单条数据格式如下:
1 | datum = {"y": 1, |
其中y是类标;text是句子原文(经过清洗);num_words是句子长度(词数);split是分配的cv索引。
- W即word matrix,W[i]是索引为i的词对应的词向量。
- W2类似于W,但是是随机初始化的。
- word_idx_map是一个dict,key是数据集中出现的word,value是该word的索引。
- vocab是一个dict,key是数据集中出现的word,value是该word出现的次数。
conv_net_classes.py:
定义具体的模型结构,不同的结构的层用不同的类定义。
如:
1 | class |
conv_net_sentences.py
完成数据的加载,模型的构建和连接,再训练模型。
5.2 数据流:
输入的数据来自rt-polarity.neg和rt-polarity.pos,原始数据是很多英文句子,类标从文件名获取。以及google的word2vec。
在process_data.py中:
1.build_data_cv():接收数据集文件,读取两个文件,生成基本数据revs(rev的内容上面已经分析)。
2.load_bin_vec():从GoogleNews-vectors-negative300.bin中加载w2v矩阵。生成w2v。w2v是一个dict,key是word,value是vector。
3.get_W():接收w2v,相当于把w2v从字典转换成矩阵W,并且生成word_idx_map。相当于原来从word到vector只用查阅w2v字典;现在需要先从word_idx_map查阅word的索引,再2用word的索引到W矩阵获取vector。
在conv_net_sentences.py中:
- 4.make_idx_data_cv():读取rev中的text字段,传入get_idx_from_sent()方法,将句子转换成一个list,list里面的元素是这句话每个词的索引。这个list形如(filter padding) - (word indices) - (Max padding) - (filter padding),长度为max_l+2×(filter_h-1),每句句子虽然本身长度不同,经过这步都转换成相同长度的list。然后,按照cv索引,分割训练集和测试集。
5.3 模型架构:
在conv_net_classes.py中:
定义了所有网络层次和具体实现:
- HiddenLayer
- DropoutHiddenLayer
- MLPDropout
- MLP
- LogisticRegression
- LeNetConvPoolLayer
这些类大多数的实现都在__init__方法中:
- 首先接收这一层的输入输出的尺寸和这一层的输入数据。
- 然后初始化这层的参数,参数都是theano.shared。
- 对于给定的输入和参数,构建这层的输出。
在conv_net_sentences.py中
获取训练数据和测试数据以后,绝大部分的工作由train_conv_net()完成:
- 传入参数分为两部分:(1)训练数据+W矩阵(2)模型结构参数
- 组建模型网络:每层的定义都在conv_net_classes.py中实现了,因此这里组建网络首先要初始化一个参数list:parameters,将每层的参数加入这个list统一管理;然后对于每一层,初始化该层的类,给该层喂入数据,获取输出;再将输出喂给下一层,依照输入输出将每一层连接起来。
- 将训练数据抽取0.1作为val数据。
- 构建function(theano.function):(1)根据cost function构建train_model;(2)构建val集的测试函数:val_model(3)构建测试集的测试函数:test_model。
- 开始训练。
6 代码重构
6.1 为什么重构
首先要明确重构代码的目的:我不是真的认为Yoon Kim的代码写的不好,我也不认为我重构完以后架构有多好;我的目的是learn by doing,通过重构代码加深对代码的理解,这是学习代码最好的方式之一。
6.2 哪里可以重构
这份代码本来就是一分学术论文的实验代码,可扩展性不高,我想用工业界的玩法去改这份代码,下面列出可以重构的地方:
- 如何定义神经网络某一层。原来的代码用一个类定义一层,这本身没有问题,但所有的细节都在__init__方法中实现,让该方法显得很臃肿,我们可以根据职责的不同,分开两个方法:init_param()和build()。也就是构建某一层神经网络最重要的两部:初始化参数和根据输入获取输出。
- train_conv_net()方法太臃肿,这一步包括了构建网络,拆分train/val,构建function,训练。一共四大步,我们应该把每步拆分开。
- 为什么没有模型的类?模型的行为类似于具体某层的行为,一层可以是类,为什么很多层组装以后反而装在一个方法里?我们也可以写一个模型类。
- 模型的结构参数为什么由方法参数传入?我们可以写一个config文件,把模型的结构参数写在这个config文件里。这样再做实验时,调模型的参数只需修改config文件。
6.3 重构细节
接下来按照上面的几点,演示下重构的细节:
- cer_main.py:加载数据,开始训练。
- cer_module.py:每层模型的实现细节。
- cer_model.py:整体模型的实现。
1.重构单层类:
重构前:
1 | class HiddenLayer(object): |
重构后:
1 | class HiddenLayer(object): |
2.重构整体模型的构建:
1 | ################################网络架构:1.初始化########################### |
3. 增加整体模型的类:CNN_Sen_Model()
类方法:
- build_model()
- train()
- build_function()
整体模型的类和具体某层的类共同点在于build,也就是给定输入获取输出的过程。不同点在于要少一个init_param()方法,因为整体模型不需要去初始化模型训练的参数,直接从细节类获取即可。另外还多一个train的方法用于模型的训练。
具体可以看我的代码。
4.将模型参数保存在model.json中:
1 | { |
来跑跑看:
1 | THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python cer_main.py |
1 | Using gpu device 0: GeForce GTX 960M (CNMeM is disabled, cuDNN not available) |
7. 结语
这篇博客记录了这个CNN Sentence Classification的基础论文和代码实现,并没有关注调参,Yoon Kim的github提到了一篇关于这种模型调参的paper,有兴趣可以去看看。
这个模型还有Tensorflow的实现,同样可以看看。