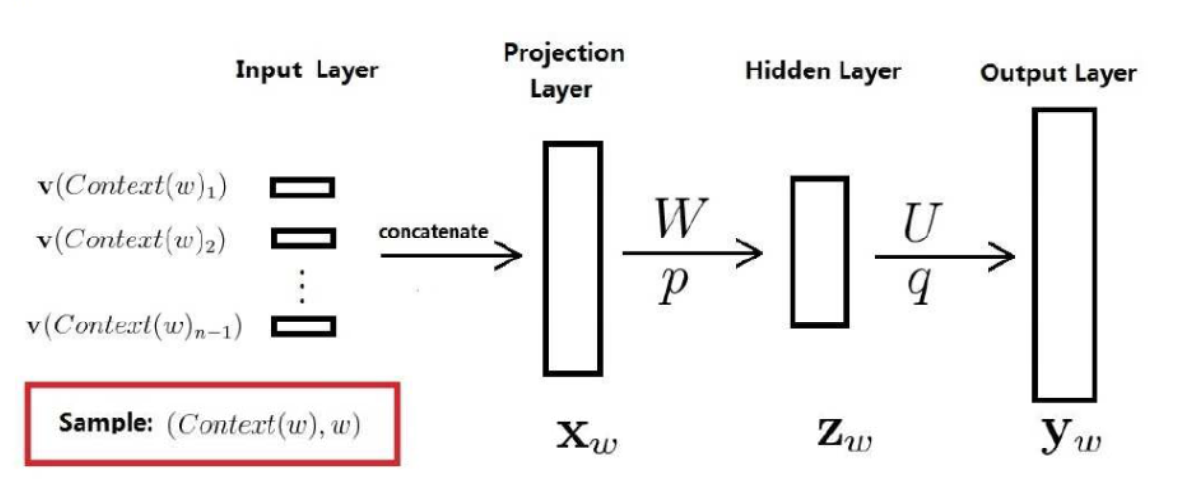
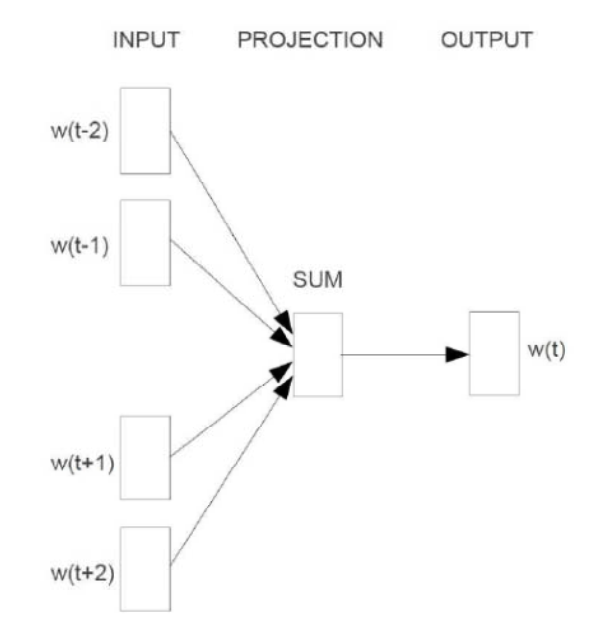
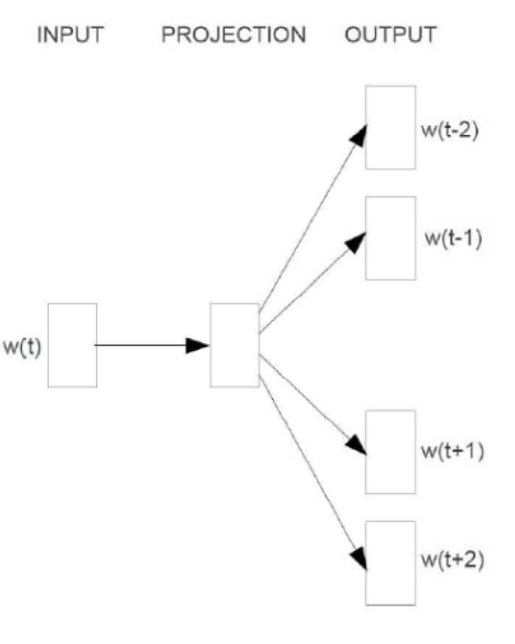
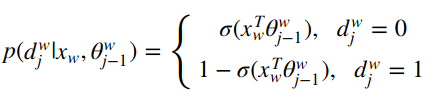1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
| WARNING:tensorflow:From <ipython-input-13-a25f3f405467>:2: initialize_all_variables (from tensorflow.python.ops.variables) is deprecated and will be removed after 2017-03-02.
Instructions for updating:
Use `tf.global_variables_initializer` instead.
Initialized
Average loss at step 0: 8.374084
Nearest to first: mistletoe, ladyland, fathered, xml, exploitable, scare, fabian, mages,
Nearest to nine: going, transferred, copacabana, lilian, dhamma, continuity, ivy, churchill,
Nearest to all: patanjali, alternates, benign, exponentially, amazons, fullback, analyzed, marlon,
Nearest to most: api, treating, rehab, objectors, disastrously, chamada, fugitives, subhas,
Nearest to or: chiapas, travels, dazzling, shag, geopolitical, below, less, granted,
Nearest to that: mozambican, tome, buddhism, concentrations, unison, allied, sotho, wu,
Nearest to use: gaff, marmalade, harford, ujjain, taxonomists, ballroom, rarity, persisted,
Nearest to into: konkan, indefatigable, ams, caret, irreverent, allman, alcal, rivalry,
Nearest to system: pressurized, pedestal, affect, powered, preferably, gcd, morning, skyview,
Nearest to were: campaigner, unusable, copyrights, wells, waterhouse, janata, touch, engraving,
Nearest to with: ranges, crystallographic, gy, condensate, rojas, bijective, maria, university,
Nearest to th: polycarbonate, irene, nik, shellfish, basenjis, measurements, reclassification, mens,
Nearest to zero: thessaly, blows, contingents, moulton, hurdler, flip, hbf, minotaurs,
Nearest to other: purchased, concluding, sicily, midwest, paranoid, hurt, ssc, cobra,
Nearest to world: deoxyribonucleic, rectum, stricken, oven, mt, diverged, pluralistic, perceptive,
Nearest to during: connelly, thirsty, nationalized, protector, lick, lockport, judgements, russcol,
Average loss at step 2000: 4.572921
Average loss at step 4000: 3.943233
Average loss at step 6000: 3.713809
Average loss at step 8000: 3.530180
Average loss at step 10000: 3.475878
Nearest to first: second, civilization, salsa, divisor, essay, braves, mikvah, tiered,
Nearest to nine: six, eight, seven, zero, five, four, two, three,
Nearest to all: many, some, these, tito, several, steadfast, other, stockton,
Nearest to most: more, tendency, waff, many, very, clerk, enhanced, juvenile,
Nearest to or: than, and, ewald, cmi, aedile, gangster, pipe, suns,
Nearest to that: which, what, marlins, gunto, who, redirected, competitors, syrups,
Nearest to use: taxonomists, specialisation, marmalade, flaherty, reason, salvador, trojans, precarious,
Nearest to into: caret, ecumenism, ams, macrocosm, thales, indefatigable, konkan, disobey,
Nearest to system: assumes, affect, compilation, handicrafts, slugs, electro, apostles, promise,
Nearest to were: are, was, being, sketch, encloses, yorkers, kekul, cadbury,
Nearest to with: rheingold, grossed, satanic, temp, mond, fairly, cavers, rickenbacker,
Nearest to th: nd, st, nine, globally, patrilineal, transhumanism, companionship, vortex,
Nearest to zero: five, nine, seven, eight, four, three, six, two,
Nearest to other: many, these, various, duquette, several, arlene, all, some,
Nearest to world: holliday, postwar, arnauld, catechism, inventive, caribs, recipient, cultivate,
Nearest to during: nas, hohenstaufen, before, cautiously, acknowledging, in, cadet, since,
Average loss at step 12000: 3.493503
Average loss at step 14000: 3.446680
Average loss at step 16000: 3.443846
Average loss at step 18000: 3.397030
Average loss at step 20000: 3.218047
Nearest to first: second, last, chaplin, buoyancy, civilization, next, most, title,
Nearest to nine: eight, seven, zero, five, two, three, six, th,
Nearest to all: many, several, various, some, lehi, chia, cal, these,
Nearest to most: more, many, tendency, very, waff, fund, some, clerk,
Nearest to or: and, than, pagos, shapeshifting, wtoo, grigory, slew, rss,
Nearest to that: which, what, where, this, when, grant, bounding, agnes,
Nearest to use: form, trojans, reason, falsified, because, specialisation, fortify, price,
Nearest to into: through, resupply, ams, within, from, in, thales, ecumenism,
Nearest to system: systems, electro, sector, orbison, violate, baptised, foonly, affect,
Nearest to were: are, was, is, have, include, pederastic, cuar, overcrowded,
Nearest to with: using, between, and, sampras, soddy, gracie, semper, generically,
Nearest to th: st, twentieth, nd, globally, nine, renminbi, worsened, alexandrian,
Nearest to zero: five, eight, seven, six, nine, four, three, two,
Nearest to other: various, different, these, both, colonisation, titration, many, tankers,
Nearest to world: amylase, metaphor, mandibles, recipient, policeman, prisoner, postwar, spans,
Nearest to during: before, since, throughout, in, until, after, through, laminated,
Average loss at step 22000: 3.358755
Average loss at step 24000: 3.296899
Average loss at step 26000: 3.254450
Average loss at step 28000: 3.287042
Average loss at step 30000: 3.228198
Nearest to first: second, last, third, next, same, largest, autonomously, best,
Nearest to nine: eight, seven, six, zero, five, four, three, two,
Nearest to all: any, many, every, some, both, various, several, each,
Nearest to most: many, some, more, less, incredible, tendency, waff, huffman,
Nearest to or: and, than, linguistics, gangster, worldstatesmen, but, like, napoli,
Nearest to that: which, this, what, where, when, however, because, syrups,
Nearest to use: sense, trojans, development, begin, cav, stampede, safety, price,
Nearest to into: through, within, in, thales, resupply, down, throughout, concocted,
Nearest to system: systems, electro, affect, violate, foonly, companies, era, rolfe,
Nearest to were: are, was, include, heero, is, have, firmness, being,
Nearest to with: between, nonnegative, soddy, timer, fingerprinting, satanic, including, letterboxed,
Nearest to th: twentieth, nd, st, nine, globally, next, renminbi, propagated,
Nearest to zero: five, nine, eight, six, seven, four, three, two,
Nearest to other: various, these, different, vespers, heterochromatin, sabina, dolphins, fingertips,
Nearest to world: catechism, decade, u, civil, mandibles, misanthropy, lrv, alcoholism,
Nearest to during: after, before, throughout, until, since, in, cordwainer, cambrian,
Average loss at step 32000: 3.013517
Average loss at step 34000: 3.205457
Average loss at step 36000: 3.187721
Average loss at step 38000: 3.158000
Average loss at step 40000: 3.159957
Nearest to first: second, last, same, best, third, next, fourth, original,
Nearest to nine: eight, seven, six, five, four, zero, two, th,
Nearest to all: every, many, any, several, some, various, fluke, certain,
Nearest to most: less, more, some, highest, authorize, many, refracting, waff,
Nearest to or: and, than, filioque, adour, directs, lamar, occult, decried,
Nearest to that: which, although, however, monatomic, evangelica, attrition, this, repudiate,
Nearest to use: sense, trojans, addition, production, achieve, begin, influx, falsified,
Nearest to into: through, within, throughout, in, down, heather, from, across,
Nearest to system: systems, foonly, program, affect, process, materiel, monitor, method,
Nearest to were: are, was, is, being, include, have, had, became,
Nearest to with: between, within, satanic, soddy, meals, without, utilizes, adage,
Nearest to th: st, nd, twentieth, globally, nine, worsened, propagated, fourth,
Nearest to zero: eight, five, four, six, seven, three, million, two,
Nearest to other: various, some, vespers, copyrighted, these, those, tether, different,
Nearest to world: u, experience, catechism, postwar, relieve, lydian, misanthropy, goodyear,
Nearest to during: after, in, since, before, throughout, within, despite, until,
Average loss at step 42000: 3.208765
Average loss at step 44000: 3.141568
Average loss at step 46000: 3.142206
Average loss at step 48000: 3.058366
Average loss at step 50000: 3.058806
Nearest to first: last, second, next, same, third, original, best, largest,
Nearest to nine: eight, seven, six, five, zero, four, th, august,
Nearest to all: several, many, some, various, multiple, these, certain, any,
Nearest to most: especially, many, more, particularly, less, refracting, discoveries, johansson,
Nearest to or: and, gangster, ewald, than, remedial, uses, yahoo, sherpa,
Nearest to that: which, although, what, because, monatomic, bounding, actually, syrups,
Nearest to use: addition, used, influx, cybernetic, admission, treatment, development, noriega,
Nearest to into: through, from, within, around, across, in, throughout, out,
Nearest to system: systems, program, process, foonly, violate, apostles, electro, region,
Nearest to were: are, was, being, is, have, had, include, be,
Nearest to with: soddy, between, using, utilizes, erase, hypoxic, primes, satanic,
Nearest to th: nd, st, twentieth, nineteenth, worsened, nine, globally, third,
Nearest to zero: eight, five, seven, four, six, two, nine, three,
Nearest to other: others, older, various, queueing, smaller, different, vespers, these,
Nearest to world: catechism, plural, label, country, policeman, romanians, abdication, postwar,
Nearest to during: throughout, until, within, in, after, since, through, following,
Average loss at step 52000: 3.099547
Average loss at step 54000: 3.092599
Average loss at step 56000: 2.922255
Average loss at step 58000: 3.034626
Average loss at step 60000: 3.047308
Nearest to first: last, second, next, third, same, earliest, original, latter,
Nearest to nine: eight, seven, six, five, four, zero, two, november,
Nearest to all: several, many, certain, various, some, every, those, both,
Nearest to most: more, especially, some, highest, particularly, greatest, waff, best,
Nearest to or: and, than, ventricle, yahoo, herders, canonised, repackaged, including,
Nearest to that: which, what, however, bao, where, when, burgh, because,
Nearest to use: cybernetic, addition, achieve, sense, tinctures, falsified, because, influx,
Nearest to into: through, within, throughout, across, around, greaves, from, towards,
Nearest to system: systems, brussel, process, program, apostles, position, adonai, informal,
Nearest to were: are, was, is, include, several, remained, being, pederastic,
Nearest to with: between, nonnegative, including, without, soddy, against, poorest, indie,
Nearest to th: twentieth, nd, st, third, globally, nineteenth, worsened, nine,
Nearest to zero: five, eight, six, seven, three, four, nine, million,
Nearest to other: various, others, queueing, older, those, different, several, these,
Nearest to world: catechism, country, condemned, label, romanians, orchids, ran, ruling,
Nearest to during: before, after, throughout, until, despite, since, over, in,
Average loss at step 62000: 3.018039
Average loss at step 64000: 2.928474
Average loss at step 66000: 2.937294
Average loss at step 68000: 2.963855
Average loss at step 70000: 3.007470
Nearest to first: last, next, second, best, earliest, same, third, fourth,
Nearest to nine: eight, th, six, zero, september, july, december, million,
Nearest to all: many, several, some, certain, various, both, every, phylum,
Nearest to most: more, especially, greatest, extremely, highest, many, less, huffman,
Nearest to or: and, than, ventricle, jewellery, gigahertz, sherpa, including, towards,
Nearest to that: which, where, bounding, monatomic, what, because, repudiate, although,
Nearest to use: practice, because, addition, trojans, outspoken, treatment, play, implementation,
Nearest to into: through, towards, across, within, toward, kearney, in, forward,
Nearest to system: systems, spearheaded, severed, decapitate, foonly, jumbo, pegbox, jermaine,
Nearest to were: are, was, is, been, newly, many, exist, potter,
Nearest to with: between, without, soddy, letterboxed, including, ehr, utilizes, satanic,
Nearest to th: nine, st, twentieth, nd, nineteenth, third, globally, worsened,
Nearest to zero: five, two, six, three, eight, seven, nine, million,
Nearest to other: various, older, mouthpieces, those, these, smaller, fewer, pikemen,
Nearest to world: catechism, orchids, plural, roller, kowloon, domesticated, u, prisoner,
Nearest to during: throughout, in, until, before, after, since, at, despite,
Average loss at step 72000: 2.943993
Average loss at step 74000: 2.870428
Average loss at step 76000: 3.000972
Average loss at step 78000: 3.000503
Average loss at step 80000: 2.843173
Nearest to first: last, next, earliest, same, second, best, original, greatest,
Nearest to nine: eight, six, seven, zero, five, three, september, th,
Nearest to all: many, any, every, several, various, some, none, both,
Nearest to most: more, many, less, some, rossellini, highest, greatest, particularly,
Nearest to or: and, but, though, herders, modifiers, than, wtoo, rss,
Nearest to that: which, this, bounding, although, where, why, because, opacity,
Nearest to use: cybernetic, practice, baptize, treatment, addition, trojans, favor, sense,
Nearest to into: through, across, within, from, out, around, forward, kearney,
Nearest to system: systems, spearheaded, foonly, severed, process, monitor, achievement, version,
Nearest to were: are, was, is, various, be, had, pederastic, newly,
Nearest to with: between, husbandry, dalai, without, letterboxed, mansfield, using, against,
Nearest to th: twentieth, st, nd, nineteenth, third, nine, rd, globally,
Nearest to zero: six, seven, eight, five, nine, four, million, three,
Nearest to other: various, these, both, others, vespers, individual, different, older,
Nearest to world: catechism, orchids, king, domesticated, ries, arnauld, country, kowloon,
Nearest to during: throughout, before, after, since, until, in, through, despite,
Average loss at step 82000: 2.942490
Average loss at step 84000: 2.895405
Average loss at step 86000: 2.918082
Average loss at step 88000: 2.947470
Average loss at step 90000: 2.828935
Nearest to first: last, next, earliest, same, best, second, original, oldest,
Nearest to nine: eight, seven, six, zero, five, th, four, late,
Nearest to all: various, some, every, many, none, several, unattested, any,
Nearest to most: especially, many, some, more, less, particularly, highest, best,
Nearest to or: and, than, while, ewald, without, moraine, tala, aka,
Nearest to that: which, where, bounding, what, this, although, who, actually,
Nearest to use: clover, outspoken, amount, because, implementation, cybernetic, standard, share,
Nearest to into: through, within, across, beyond, out, from, forward, throughout,
Nearest to system: systems, brussel, spearheaded, sector, process, pls, violate, apostles,
Nearest to were: are, was, is, newly, rabid, had, be, include,
Nearest to with: between, without, hypoxic, letterboxed, fingerprinting, involving, when, featuring,
Nearest to th: nd, twentieth, st, nine, next, fourth, nineteenth, third,
Nearest to zero: five, eight, six, four, nine, three, seven, two,
Nearest to other: others, fewer, various, older, different, these, monstrous, soaring,
Nearest to world: catechism, orchids, nordic, domesticated, country, puritan, arnauld, plural,
Nearest to during: throughout, after, in, before, since, at, until, over,
Average loss at step 92000: 2.886946
Average loss at step 94000: 2.881201
Average loss at step 96000: 2.710057
Average loss at step 98000: 2.458667
Average loss at step 100000: 2.709969
Nearest to first: last, next, second, earliest, best, third, greatest, same,
Nearest to nine: eight, seven, five, six, four, zero, three, th,
Nearest to all: every, many, various, several, some, any, always, both,
Nearest to most: particularly, more, especially, some, less, many, highly, increasingly,
Nearest to or: and, than, but, ewald, while, rss, canonised, whereas,
Nearest to that: which, where, although, when, whom, opacity, bounding, monatomic,
Nearest to use: version, usage, clover, practice, influx, treatment, consisted, amount,
Nearest to into: through, across, down, within, beyond, out, towards, from,
Nearest to system: systems, brussel, process, corporation, era, bachelor, concept, spearheaded,
Nearest to were: are, was, include, is, exist, had, have, contain,
Nearest to with: between, through, without, among, amongst, hypoxic, celtics, involving,
Nearest to th: twentieth, nd, nineteenth, fourth, rd, st, tenth, seventh,
Nearest to zero: five, eight, four, seven, six, three, two, nine,
Nearest to other: fewer, others, both, older, these, various, smaller, monstrous,
Nearest to world: catechism, orchids, u, domesticated, falklands, ephesus, cartographer, nordic,
Nearest to during: throughout, despite, in, until, since, at, after, within,
|