基于朴素贝叶斯的自然语言分类器
概述
1 | 自然语言分类是指按照预先定义的主题类别,为文档集合中的每个文档确定一个类别。 |
一、训练数据获取
中文自然语言分类现成可用的有搜狗自然语言分类语料库、北京大学建立的人民日报语料库、清华大学建立的现代汉语语料库等。
由于语言在使用过程中会不断演进,具有一定的时效性,我们最终决定自己开发爬虫爬取训练数据。
经过综合考虑,我们最终将目标选定为凤凰网。
我们选取凤凰网移动版开展数据获取工作,地址为http://i.ifeng.com/ 如图1所示。
移动版的页面布局简单清晰,但由于文章列表采用了下拉刷新的动态更新策略,直接解析页面源码效率太低,最终决定直接调用网页api获取。比如获取十条凤凰“军事”的内容,访问http://imil.ifeng.com/20_2/data.shtml 返回结果如图2左。
最终获取到4784条新闻,都保存到MySQL数据库,具体数据如图2右。
从中看出,军事类的文章相对偏少,体育类的文章偏多。

二、朴素贝叶斯介绍
1.贝叶斯定理
贝叶斯定理是关于随机事件 A 和 B 的条件概率:

其中,P(A)是A的先验概率,之所以称为“先验”是因为它不考虑任何B方面的因素。
P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A 的后验概率。
P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
P(B)是B的先验概率,也称作标淮化常量(normalizing constant)。
按这些术语,贝叶斯定理可表述为:
$后验概率 = (相似度 * 先验概率)/标淮化常量$
2.贝叶斯概率观
一般学院派的概率观可以称作频率主义。一个事件,如果重复独立地执行多次,把发生的次数除以执行的次数,就得到一个频率。比如说抛硬币,抛了10000次,有4976次正面向上,频率就是0.4976。然后如果执行的次数很多很多,频率会趋向于一个固定的值,就是这个事件的概率。理论基础是中心极限定理。
贝叶斯概率观与此很不同。
主观贝叶斯主义认为,概率就是个人对某个事件发生可能性的一个估计。
如果对一个事件你一无所知,那么你可以随便猜一个概率。
但因为是估计,如果有新的信息,那就必须根据新信息对概率进行修正。
这样的话,随着经历越来越多,对概率的估计也会越来越符合“实际情况”。
3.朴素贝叶斯分类器
分类器基本原理:
对一个多维的输入向量x,根据贝叶斯公式,有:

条件独立性假设:
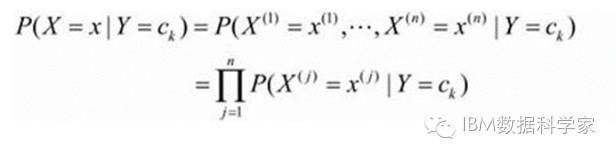
放到自然语言分类器的应用中理解,就是在给定文本的类别的条件下,文本中出现的词的概率是相互独立的。
朴素贝叶斯之所以“朴素”,就是因为条件独立性假设是一个较强的假设。于是:


从自然语言分类的角度上说,一个文本属于哪个类,要计算所有类别的先验概率和所有词在相应类别下的后验概率,再一起乘起来,哪个类别对应的值最大,就归为哪类。



三、分类器实现
1.数据预处理
文本放到分类器中分类,必须先将文本数据向量化,因为scikit-learn的分类器大多输入的数据类型都是numpy数组和类似的类型。
这一步可以通过scikit-learn中特征抽取模块feature_extraction中text.
CountVectorizer、text.TfidfVectorizer和text.HashingVectorizer实现。

特征哈希:特征哈希是一种处理高维数据的技术,并经常被应用在文本和分类数据集。
特征哈希不需要像其他向量化工具一样,需要额外对数据集做一次遍历。
特征哈希通过使用哈希方差对特征赋予向量下标,这个向量下标是通过对特征,例如,单词“美国”计算的哈希值是342,那么向量中下标是342的那个元素,值加1。
特征哈希的优势在于不需要构建映射并把它保存到内存中,但是需要预先选择特征向量的大小。
另外,在向量化之前,还有一步是十分必要的。
上述的方法是针对英文设计实现的,因此接收的数据类型也是默认通过空格的截断获取分词结果。
因此要讲中文向量化,必须要先分词。
这一步我们通过jieba实现。最后的输入文本类似图3这样的格式。
CountVectorize的转换结果如图4,向量的每个值代表一个词出现的个数。
HashingVectorizer的转换结果如图5。
TfidfVectorizer的转换结果如图6,这里我们设置参数use_idf=False,即只使用tf,但并不等同于CountVectorize,而是相当于个数+归一化。




2.调参
确定了模型之后,可以直接使用Scikit-learn中的GridSearchCV来寻找最佳超参数。
另外一个提高准确率的技巧是删除停用词。
之前分词的过程中使用的是通用的中文停用词,比如“这”,“那”等没有实际语义的词。
但是这里对于文章的分类来说还有一些高频出现但是对主题没有影响的词,即便他们本身是有语义的。
比如“时间”、“图”等。

3.组合
组合技术即通过聚集多个分类器的预测来提高分类准确率。
常用的组合分类器方法:
1)装袋(bagging):根据均匀概率分布从数据集中重复抽样(有放回),每个自助样本集和原数据集一样大,每个自助样本集含有原数据集大约63%的数据。训练k个分类器,测试样本被指派到得票最高的类。
2)提升(boosting):通过给样本设置不同的权值,每轮迭代调整权值。不同的提升算法之间的差别,一般是(1)如何更新样本的权值;(2)如何组合每个分类器的预测。其中在Adaboost中,样本权值是增加那些被错误分类的样本的权值,分类器C_i的重要性依赖于它的错误率。
这里使用BaggingClassifier对原分类器进行装袋组合,准确率有所提升。
四、分类器评估
使用scikit-learn提供的classification_report获得分类报告如图8。
使用condusion_matrix获得分类混淆矩阵如图9。交叉验证的结果如图10。
可见,取得了较理想的分类表现。图11是部分分类结果。



