一. intro
1 | 对应本书第一章。 |
0.简介
https://raw.githubusercontent.com/applenob/algorithm_note/master/res/cover.jpg
这本书的豆瓣评分高达9.3,python作为接近算法伪码的一种脚本语言,其实用它写算法是极好的,可以将注意力集中在算法本身。
但是由于python性能的问题,用python写算法不算太主流,因此市面上介绍算法的书也多以使用c/c++或者Java居多。
这本书几乎是用python介绍算法豆瓣评分最高的一本书了,网上可以下到pdf,但最好的阅读方式是直接使用这本书的网站。这本书可以直接在网站上运行示例程序。self check的部分还有作者视频讲解,这才是编程类书籍的未来嘛!
这里我记录每章的学习笔记,同时记录每章课后作业的个人解决代码,统一使用python3。
遗传算法(Genetic Algorithm)
这篇博客记录自己学习遗传算法的心得。
引入
关于遗传算法,在知乎的问题如何通俗易懂地解释遗传算法?有什么例子?是一个很好的资料,介绍了很多很有趣的例子。
我第一次对遗传算法感兴趣是听了卓老板的一个介绍复杂系统的音频节目,这个节目引用了《复杂》这本书中的关于遗传算法的例子。即一个吃豆人的例子,知乎也有提到。很有意思,也很有启发性,于是想研究研究代码,顺带做个总结。
来自遗传学的启发
CNN Sentence Classification (with Theano code)
1. Intro
1 | 本篇博客来细说CNN在NLP中的一大应用————句子分类。通过Yoon Kim的论文介绍一个应用,分析代码,并重构代码。 |
传统的句子分类器一般使用SVM和Naive Bayes。传统方法使用的文本表示方法大多是“词袋模型”。即只考虑文本中词的出现的频率,不考虑词的序列信息。传统方法也可以强行使用N-gram的方法,但是这样会带来稀疏问题,意义不大。
CNN(卷积神经网络),虽然出身于图像处理,但是它的思路,给我们提供了在NLP应用上的参考。“卷积”这个术语本身来自于信号处理,它的物理意义可以参考知乎上关于“复利”的回答,或者参考colah大神的博客。简单地说就是一系列的输入信号进来之后,系统也会有一系列的输出。但是并不是某一时刻的输出只对应该时刻的输入,而是根据系统自身的特征,每一个时刻的输出,都和之前的输入相关。那么如果文本是一些列输入,我们当然希望考虑词和词的序列特征,比如“Tom的 手机 ”,使用卷积,系统就会知道“手机是tom”的,而不是仅仅是一个“手机”。
或者更直观地理解,在CNN模型中,卷积就是拿kernel在图像上到处移动,每移动一次提取一次特征,组成feature map,
这个提取特征的过程,就是卷积。
Word2Vec学习总结
1 | Word2Vec学习笔记,附带Tensorflow的CBOW实现。 |
神经概率语言模型
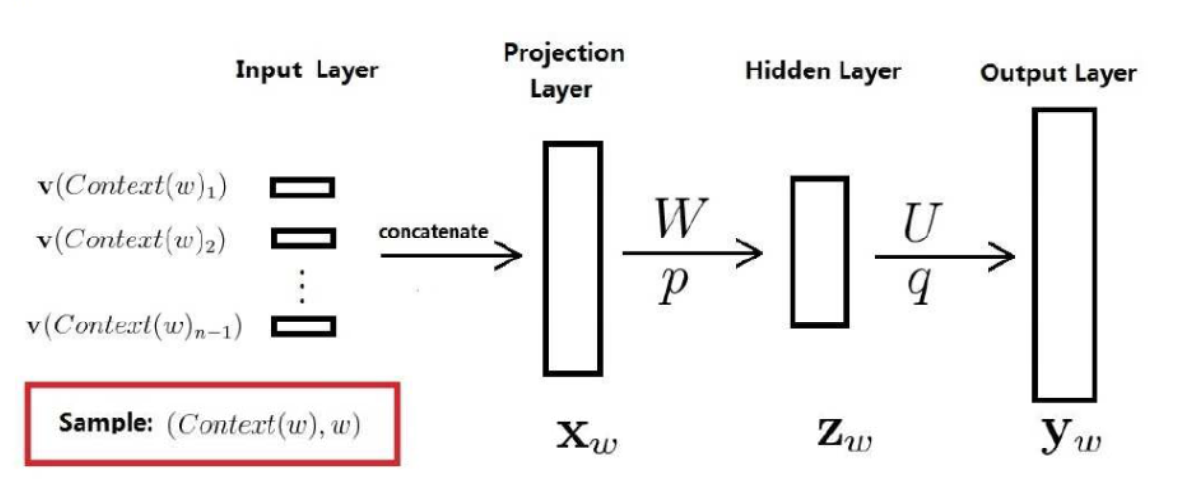
- 词向量:$v(w) \in R^m$
- $m$是词向量的维度,通常是$10^1\sim 10^2$的量级。
- 神经网络参数:$W \in R^{n_h×(n-1)m}$,$p \in R^{n_h}$,$U\in R^{n_h×N}$,$q \in R^N$
- $n$:上下文词数,通常不超过5。
- $n_h$:隐层的维度,用户指定,通常是$10^2$的量级。
- $N$:语料的大小,通常是$10^4\sim 10^5$的量级。
- 通过神经网络的反向传播,更新$v(w)$,最终获得w2v。
- $x_w$是各词向量之和。
{kind=link}